
Slashdot's CmdrTaco points us to a research project announced by EFF‘s Peter Eckersley that I expect will provoke both discussion and action:
What fingerprints does your browser leave behind as you surf the web?
Traditionally, people assume they can prevent a website from identifying them by disabling cookies on their web browser. Unfortunately, this is not the whole story.
When you visit a website, you are allowing that site to access a lot of information about your computer's configuration. Combined, this information can create a kind of fingerprint – a signature that could be used to identify you and your computer. But how effective would this kind of online tracking be?
EFF is running an experiment to find out. Our new website Panopticlick will anonymously log the configuration and version information from your operating system, your browser, and your plug-ins, and compare it to our database of five million other configurations. Then, it will give you a uniqueness score – letting you see how easily identifiable you might be as you surf the web.
Adding your information to our database will help EFF evaluate the capabilities of Internet tracking and advertising companies, who are already using techniques of this sort to record people's online activities. They develop these methods in secret, and don't always tell the world what they've found. But this experiment will give us more insight into the privacy risk posed by browser fingerprinting, and help web users to protect themselves.
To join the experiment:
http://panopticlick.eff.org/To learn more about the theory behind it:
http://www.eff.org/deeplinks/2010/01/primer-information-theory-and-priva…
Interesting that my own browser was especially recognizable:
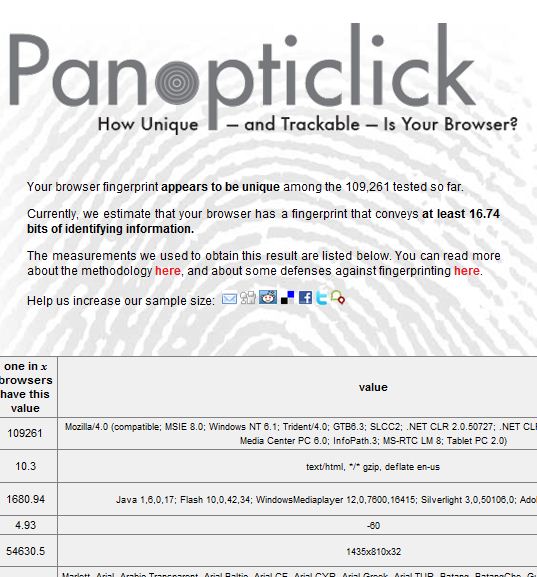
I know my video configuration is pretty bizarre – but don't understand why I should be broadcasting that when I casually surf the web. I would also like to understand what is so special about my user agent info.
Pixel resolution like 1435 x 810 x 32 seems unnecessarily specific. Applying the concept of minimal disclosure, it would be better to reveal simply that my machine is in some useful “class” of resolution that would not overidentify me.
I would think the provisioning of highly identifying information should be limited to sites with which I have an identity relationship. If we can agree on a shared mechanism for storing information about our trust for various sites (information cards offer this capability) our browsers could automatically adjust to the relationship they were in, releasing information as necessary. This is a good example of how a better identity system is needed to protect privacy while providing increased functionality.