Students at Ruhr Universitat Bochum in Germany have published an account this week describing an attack on the use of CardSpace within Internet Explorer. Their claim is to “confirm the practicability of the attack by presenting a proof of concept implementation“.
I’ve spent a fair amount of time reproducing and analyzing the attack. The students were not actually able to compromise my safety except by asking me to go through elaborate measures to poison my own computer (I show how complicated this is in a video I will post next). For the attack to succeed, the user has to bring full administrative power to bear against her own system. It seems obvious that if people go to the trouble to manually circumvent all their defenses they become vulnerable to the attacks those defenses were intended to resist. In my view, the students did not compromise CardSpace.
DNS must be undermined through a separate (unspecified) attack
To succeed, the students first require a compromise of a computer’s Domain Name System (DNS). They ask their readers to reconfigure their computers and point to an evil DNS site they have constructed. Once we help them out with this, they attempt to exploit the fact that poisoned DNS allows a rogue site and a legitimate site to appear to have the same internet “domain name” (e.g. www.goodsite.com) . Code in browser frames animated by one domain can interact with code from other frames animated by the same domain. So once DNS is compromised, code supplied by the rogue site can interfere with the code supplied by the legitimate site. The students want to use this capability to hijack the legitimate site’s CardSpace token.
However, the potential problems of DNS are well understood. Computers protect themselves from attacks of this kind by using cryptographic certificates that guarantee a given site REALLY DOES legitimately own a DNS name. Use of certificates prevents the kind of attack proposed by the students.
The certificate store must also “somehow be compromised”
But this is no problem as far as the students are concerned. They simply ask us to TURN OFF this defense as well. In other words, we have to assist them by poisoning all of the safeguards that have been put in place to thwart their attack.
Note that both safeguards need to be compromised at the same time. Could such a compromise occur in the wild? It is theoretically possible that through a rootkit or equivalent, an attacker could completely take over the user’s computer. However, if this is the case, the attacker can control the web browser, see and alter everything on the user’s screen and on the computer as a whole, so there is no need to obtain the CardSpace token.
I think it is amazing that the Ruhr students describe their attack as successful when it does NOT provide a method for compromising EITHER DNS or the certificate store. They say DNS might be taken over through a drive-by attack on a badly installed wireless home network. But they provide no indication of how to simultaneously compromise the Root Certificate Store.
In summary, the students’ attack is theoretical. They have not demonstrated the simultaneous compromise of the systems necessary for the attack to succeed.
The user experience
Because of the difficulty of compromising the root certificate store, let’s look at what would happen if only DNS were attacked.
Internet Explorer does a good job of informing the user that she is in danger and of advising her not to proceed.
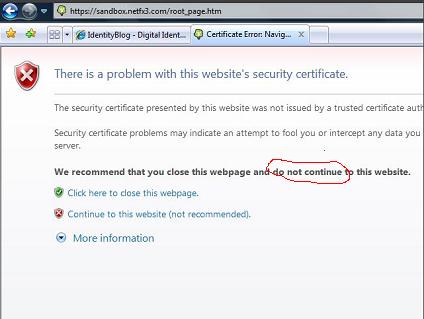
First the user encounters the following screen, and has to select “Continue to the website (not recommended)”:
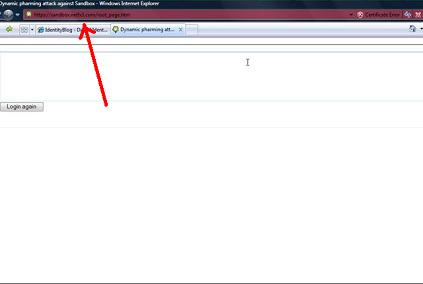
If recalcitrant, the user next sees an ominous red band warning within the address bar and an unnaturally long delay:
The combined attacks require a different yet coordinated malware delivery mechanism than a visit to the phishing site provides. In other words, accomplishing two or more attacks simultaneously greatly reduces the likelihood of success.
The students’ paper proposes adding a false root certificate that will suppress the Internet Explorer warnings. As is shown in the video, this requires meeting an impossibly higher bar. The user must be tricked into importing a “root certificate”. This by default doesn’t work – the system protects the user again by installing the false certificate in a store that will not deceive the browser. Altering this behavior requires a complex manual override.
However, should all the planets involved in the attack align, the contents of the token are never visible to the attacker. They are encrypted for the legitimate party, and no personally identifying information is disclosed by the system. This is not made clear by the students’ paper.
What the attempt proves
The demonstrator shows that if you are willing to compromise enough parts of your system using elevated access, you can render your system attackable. This aspect of the students’ attack is not noteworthy.
There is, however, one interesting aspect to their attack. It doesn’t concern CardSpace, but rather the way intermittent web site behavior can be combined with DNS to confuse the browser. The student’s paper proposes implementing a stronger “Same Origin Policy” to deal with this (and other) possible attacks. I wish they had concentrated on this positive contribution rather than making claims that require suspension of disbelief.
The students propose a mechanism for associating Information Card tokens with a given SSL channel. This idea would likely harden Information Card systems and is worth evaluating.
However, the students propose equipping browsers with end user certificates so the browsers would be authenticated, rather than the sites they are visiting. This represents a significant privacy problem in that a single tracking key would be used at all the sites the user visits. It also doesn’t solve the problem of knowning whether I am at a “good” site or not. The problem here is that if duped, I might provide an illegitimate site with information which seriously damages me.
One of the most important observations that must be made is that security isn’t binary – there is no simple dichotomy between vulnerable and not-vulnerable. Security derives from concentric circles of defense that act cumulatively and in such a way as to reinforce one another. The title of the students’ report misses this essential point. We need to design our systems in light of the fact that any system is breachable. That’s what we’ve attempted to do with CardSpace. And that’s why there is an entire array of defenses which act together to provide a substantial and practical barrier against the kind of attack the students have attempted to achieve.