
Gunnar Peterson has written many good things about architecture and identity over the last few years. Now he lays down the guantlet and challenges cloud advocates with a great video that throws all the fundamental issues into sardonic relief. Everyone involved with the cloud should watch this video repeatedly and come back with really good answers to all that is implied and questioned… albeit through humor.

Month: February 2010
Not Invented Here
There's a new comic strip about software with the, um, mysterious title, Not Invented Here (I just caught the preposterous domain name: http://notinventedhe.re)… The strip deals with issues like security, and comments posted by readers say things like, “I DEMAND you take the bug out of my company's conference room immediately!” and “Wow, it is as if you have a mole in our office!”. So, with the authors’ permission, here's a taste.
It all starts off innocently enough:

Wait. I think I've met these people.

Yikes. Maybe I am these people!

And if you're in the business, you can't miss this one, which will take you over to the NIH site.
If you're wondering where this can possibly come from, the strip is by Bill Barnes and Paul Southworth. I don't know Paul yet, but readers may know Bill's work from Unshelved, which has been making librarians guffaw for years (an easy task?) The truth is, Bill knows a lot about what goes on with software – in fact one of his gigs was herding cats during the first version of CardSpace. Now he's totally dedicated to his strips – should be a lot of fun – and enlightening too.
Enterprise lockdown versus consumer applications
My friend Cameron Westland, who has worked on some cool applications for the iPhone, wrote me to complain that I linked to iPhone Privacy:
I understand the implications of what you are trying to say, but how is this any different from Mac OS X applications accessing the address book or Windows applications accessing contacts? (I'm not sure about Windows, but I know it's possible on a Mac).
Also, the article touches on storing patient information on an iPhone. I believe Seriot is guilty of a major oversight in simply correlating the fact that spy phone has access to contacts with it also being able to do so in a secured enterprise.
If the iPhone is deployed in the enterprise, the corporate administrators can control exactly which applications get installed. In the situations where patient information is stored on the phone, they should be using their own security review process to verify that all applications installed meet the HIPPA certification requirements. Apple makes no claim that applications meet the stringent needs of certain industries – that's why they give control to administrators to encrypt phones, restrict specific application installs, and do remote wipes.
Also, Seriot did no research behavior of a phone connected to a company's active directory, versus just plain old address book… This is cargo cult science at best, and I'm really surprised you linked to it!
I buy Cameron's point that the controls available to enterprises mitigate a number of the attacks presented by Seriot – and agree this is important. How do these controls work? Corporate administrators can set policies specifying the digital signatures of applications that can be installed. They can use their own processes to decide what applications these will be.
None of this depends on App Store verification, sandboxing, or Apple's control of platform content. In fact it is no different from the universally available ability to use a combination of enterprise policy and digital signature to protect enterprise desktop and server systems. Other features, like the ability for an operator to wipe information, are also pretty much universal.
If the iPhone can be locked down in enterprises, why is Seriot's paper still worth reading? Because many companies and even governments are interested in developing customer applications that run on phones. They can't dictate to customers what applications to install, and so lock-down solutions are of little interest. They turn to Apple's own claims about security, and find statements like this one, taken from the otherwise quite interesting iPhone security overview.
Runtime Protection
Applications on the device are “sandboxed” so they cannot access data stored by other applications. In addition, system files, resources, and the kernel are shielded from the user’s application space. If an application needs to access data from another application, it can only do so using the APIs and services provided by iPhone OS. Code generation is also prevented.
Seriot shows that taking this claim at face value would be risky. As he says in an eWeek interview:
“In late 2009, I was involved in discussions with the Swiss private banking industry regarding the confidentiality of iPhone personal data,” Seriot told eWEEK. “Bankers wanted to know how safe their information [stores] were, which ones are exactly at risk and which ones are not. In brief, I showed that an application downloaded from the App Store to a standard iPhone could technically harvest a significant quantity of personal data … [including] the full name, the e-mail addresses, the phone number, the keyboard cache entries, the Wi-Fi connection logs and the most recent GPS location.”
It is worth noting that Seriot's demonstration is very easy to replicate, and doesn't depend on silly assumptions like convincing the user to disable their security settings and ignore all warnings.
The points made about banking applications apply even more to medical applications. Doctors are effectively customers from the point of view of the information management services they use. Those services won't be able to dictate the applications their customers deploy. I know for sure that my doctor, bless his soul, doesn't have an IT department that sets policies limiting his ability to play games or buy stocks. If he starts using his phone for patient-related activities, he should be aware of the potential issues, and that's what MedPage was talking about.
Neither MedPage, nor CNET, nor eWeek nor Seriot nor I are trying to trash the iPhone – it's just that application isolation is one of the hardest problems of computer science. We are pointing out that the iPhone is a computing device like all the others and subject to the same laws of digital physics, despite dangerous mythology to the contrary. On this point I don't think Cameron Westland and I disagree.
SpyPhone for iPhone
The MedPage Today blog recently wrote about “iPhone Security Risks and How to Protect Your Data — A Must-Read for Medical Professionals.” The story begins:
Many healthcare providers feel comfortable with the iPhone because of its fluid operating system, and the extra functionality it offers, in the form of games and a variety of other apps. This added functionality is missing with more enterprise-based smart phones, such as the Blackberry platform. However, this added functionality comes with a price, and exposes the iPhone to security risks.
Nicolas Seriot, a researcher from the Swiss University of Applied Sciences, has found some alarming design flaws in the iPhone operating system that allow rogue apps to access sensitive information on your phone.
MedPage quotes a CNET article where Elinor Mills reports:
Lax security screening at Apple's App Store and a design flaw are putting iPhone users at risk of downloading malicious applications that could steal data and spy on them, a Swiss researcher warns.
Apple's iPhone app review process is inadequate to stop malicious apps from getting distributed to millions of users, according to Nicolas Seriot, a software engineer and scientific collaborator at the Swiss University of Applied Sciences (HEIG-VD). Once they are downloaded, iPhone apps have unfettered access to a wide range of privacy-invasive information about the user's device, location, activities, interests, and friends, he said in an interview Tuesday…
In addition, a sandboxing technique limits access to other applications’ data but leaves exposed data in the iPhone file system, including some personal information, he said.
To make his point, Seriot has created open-source proof-of-concept spyware dubbed “SpyPhone” that can access the 20 most recent Safari searches, YouTube history, and e-mail account parameters like username, e-mail address, host, and login, as well as detailed information on the phone itself that can be used to track users, even when they change devices.

Following the link to Seriot's paper, called iPhone Privacy, here is the abstract:
It is a little known fact that, despite Apple's claims, any applications downloaded from the App Store to a standard iPhone can access a significant quantity of personal data.
This paper explains what data are at risk and how to get them programmatically without the user's knowledge. These data include the phone number, email accounts settings (except passwords), keyboard cache entries, Safari searches and the most recent GPS location.
This paper shows how malicious applications could pass the mandatory App Store review unnoticed and harvest data through officially sanctioned Apple APIs. Some attack scenarios and recommendations are also presented.
In light of Seriot's paper, MedPage concludes:
These security risks are substantial for everyday users, but become heightened if your phone contains sensitive data, in the form of patient information, and when your phone is used for patient care. Over at iMedicalApps.com, we are not fans of medical apps that enable you to input patient data, and there are several out there. But we also have peers who have patient contact information stored on their phones, patient information in their calendars, or are accessible to their patients via e-mail. You can even e-prescribe using your iPhone.
I don't want to even think about e-prescribing using an iPhone right now, thank you.
Anyone who knows anything about security has known all along that the iPhone – like all devices – is vulnerable to some set of attacks. For them, iPhone Privacy will be surprising not because it reveals possible attacks, but because of how amazingly elementary they are (the paper is a must-read from this point of view).
On a positive note, the paper might awaken some of those sent into a deep sleep by proselytizers convinced that Apple's App Store censorship program is reasonable because it protects them from rogue applications.
Evidently Apple's App Store staff take their mandate to protect us from people like award winning Mad Magazine cartoonist Tom Richmond pretty seriously (see Apple bans Nancy Pelosi bobble head). If their approach to “protecting” the underlying platform has any merit at all, perhaps a few of them could be reassigned to work part time on preventing trivial and obvious hacker exploits..
But I don't personally think a closed platform with a censorship board is either the right approach or one that can possibly work as attackers get more serious (in fact computer science has long known that this approach is baloney). The real answer will lie in hard, unfashionable and (dare I say it?) expensive R&D into application isolation and related technologies. I hope this will be an outcome: first, for the sake of building a secure infrastructure; second, because one of my phones is an iPhone and I like to explore downloaded applications too.
[Heads Up: Khaja Ahmed]
Sorry Tomek, but I “win”
As I discussed here, the EFF is running an experimental site demonstrating that browsers ooze an unnecessary “browser fingerprint” allowing users to be identified across sites without their knowledge. One can easily imagine this scenario:
- Site “A” offers some service you are interested in and you release your name and address to it. At the same time, the site captures your browser fingerprint.
- Site “B” establishes a relationship with site “A” whereby when it sends “A” a browser fingerprint and “A” responds with the matching identifying information.
- You are therefore unknowingly identified at site “B”.
I can see browser fingerprints being used for a number of purposes. Some sites might use a fingerprint to keep track of you even after you have cleared your cookies – and rationalize this as providing added security. Others will inevitably employ it for commercial purposes – targeted identifying customer information is high value. And the technology can even be used for corporate espionage and cyber investigations.
It is important to point out that like any fingerprint, the identification is only probabilistic. EFF is studying what these probabilities are. In my original test, my browser was unique in 120,000 other browsers – a number I found very disturbing.
But friends soon wrote back to report that their browser was even “more unique” than mine! And going through my feeds today I saw a post at Tomek's DS World where he reported a staggering fingerprint uniqueness of 1 in 433,751:

It's not that I really think of myself as super competitive, but these results were so extreme I decided to take the test again. My new score is off the scale:

Tomek ends his post this way:
“So a browser can be used to identify a user in the Internet or to harvest some information without his consent. Will it really become a problem and will it be addressed in some way in browsers in the future? This question has to be answered by people responsible for browser development.”
I have to disagree. It is already a problem. A big problem. These outcomes weren't at all obvious in the early days of the browser. But today the writing is on the wall and needs to be addressed. It's a matter right at the core of delivering on a trustworthy computing infrastructure. We need to evolve the world's browsers to employ minimal disclosure, releasing only what is necessary, and never providing a fingerprint without the user's consent.
More unintended consequences of browser leakage
Joerg Resch at Kuppinger Cole points us to new research showing how social networks can be used in conjunction with browser leakage to provide accurate identification of users who think they are browsing anonymously.
Joerg writes:
Thorsten Holz, Gilbert Wondracek, Engin Kirda and Christopher Kruegel from Isec Laboratory for IT Security found a simple and very effective way to identify a person behind a website visitor without asking for any kind of authentication. Identify in this case means: full name, adress, phone numbers and so on. What they do, is just exploiting the browser history to find out, which social networks the user is a member of and to which groups he or she has subscribed within that social network.
The Practical Attack to De-Anonymize Social Network Users begins with what is known as “history stealing”.
Browsers don’t allow web sites to access the user’s “history” of visited sites. But we all know that browsers render sites we have visited in a different color than sites we have not. This is available programmatically through javascript by examining the a:visited style. So malicious sites can play a list of URLs and examine the a:visited style to determine if they have been visited, and can do this without the user being aware of it.
This attack has been known for some time, but what is novel is its use. The authors claim the groups in all major social networks are represented through URLs, so history stealing can be translated into “group membership stealing”. This brings us to the core of this new work. The authors have developed a model for the identification characteristics of group memberships – a model that will outlast this particular attack, as dramatic as it is.
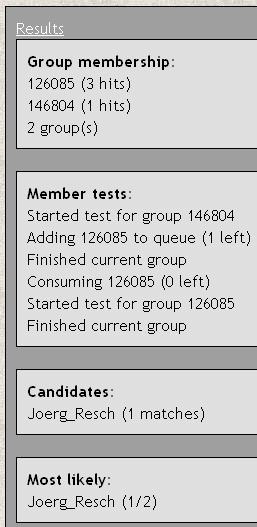
The researchers have created a demonstration site that works with the European social network Xing. Joerg tried it out and, as you can see from the table at left, it identified him uniquely – although he had done nothing to authenticate himself. He says,
“Here is a screenshot from the self-test I did with the de-anonymizer described in my last post. I´m a member in 5 groups at Xing, but only active in just 2 of them. This is already enough to successfully de-anonymize me, at least if I use the Google Chrome Browser. Using Microsoft Internet Explorer did not lead to a result, as the default security settings (I use them in both browsers) seem to be stronger. That´s weird!”
Since I’m not a user of Xing I can’t explore this first hand.
Joerg goes on to ask if history-stealing is a crime? If it’s not, how mainstream is this kind of analysis going to become? What is the right legal framework for considering these issues? One thing for sure: this kind of demonstration, as it becomes widely understood, risks profoundly changing the way people look at the Internet.
To return to the idea of minimal disclosure for the browser, why do sites we visit need to be able to read the a:visited attribute? This should again be thought of as “fingerprinting”, and before a site is able to retrieve the fingerprint, the user must be made aware that it opens the possibility of being uniquely identified without authentication.