Since then one recurring question people have had is why I thought the GDPR regulation, which only applies in Europe, would have a broad international impact, since “things are so different in the US”.
First, the same issues that led the European Union to create the GDPR impact all societies. There are countless people in America and elsewhere who have lost all confidence in the Internet giants to protect their data or their interests. This has already given rise to social sentiment that is motivating political leaders to get on the right side of history – introducing data privacy legislation. And in the discussion around what this will be, the GDPR has set the bar and established expectations that make it easy to lead campaigns describing what bad legislation is missing.
Second, all sentient beings within the internet companies understand the fundamental nature of the internet: it is world-wide and cannot be bifurcated. Building reliable, defensible services that behave differently in Europe and North America is a no-win proposition. Technology companies have lobbied for international harmonization of regulations for many years. Over time practicality will push those who choose to bifurcate and ignore the internet’s fundamental nature back to this principle.
Microsoft, which operates a number of giant internet services, saw from the beginning that the GDPR was consistent with humanistic aspirations and that formalizing protections in the ways specified by the GDPR was simply a best practice that should apply to every service we operate everywhere. Satya Nadella has consistently supported not only the GDPR, but the citizen’s right to identity and privacy, and beyond that, the whole principle of user-centric computing and giving people control of and access to their data.
But those with doubts about the world-wide impact of GDPR can now also read carefully the truly remarkable speech given Wednesday by Apple’s Tim Cook. He makes it absolutely clear that Apple sees the GDPR as a fundamental technology building-block and fully understands that the EU has effectively pushed the digital reset button world-wide – and that this is hugely positive.
Good morning.
It is an honor to be here with you today in this grand hall, a room that represents what is possible when people of different backgrounds, histories and philosophies come together to build something bigger than themselves.
I am deeply grateful to our hosts. I want to recognize Ventsislav Karadjov for his service and leadership. And it’s a true privilege to be introduced by his co-host, a statesman I admire greatly, Giovanni Butarelli.
Now Italy has produced more than its share of great leaders and public servants. Machiavelli taught us how leaders can get away with evil deeds, and Dante showed us what happens when they get caught.
Giovanni has done something very different. Through his values, his dedication, his thoughtful work, Giovanni, his predecessor Peter Hustinx — and all of you — have set an example for the world. We are deeply grateful.
We need you to keep making progress — now more than ever. Because these are transformative times. Around the world, from Copenhagen to Chennai to Cupertino, new technologies are driving breakthroughs in humanity’s greatest common projects. From preventing and fighting disease, to curbing the effects of climate change, to ensuring every person has access to information and economic opportunity.
At the same time, we see vividly — painfully — how technology can harm rather than help. Platforms and algorithms that promised to improve our lives can actually magnify our worst human tendencies. Rogue actors and even governments have taken advantage of user trust to deepen divisions, incite violence and even undermine our shared sense of what is true and what is false.
This crisis is real. It is not imagined, or exaggerated, or crazy. And those of us who believe in technology’s potential for good must not shrink from this moment.
Now, more than ever — as leaders of governments, as decision-makers in business and as citizens — we must ask ourselves a fundamental question: What kind of world do we want to live in?
I’m here today because we hope to work with you as partners in answering this question.
At Apple, we are optimistic about technology’s awesome potential for good. But we know that it won’t happen on its own. Every day, we work to infuse the devices we make with the humanity that makes us. As I’ve said before, technology is capable of doing great things. But it doesn’t want to do great things. It doesn’t want anything. That part takes all of us.
That’s why I believe that our missions are so closely aligned. As Giovanni puts it, we must act to ensure that technology is designed and developed to serve humankind, and not the other way around.
We at Apple believe that privacy is a fundamental human right. But we also recognize that not everyone sees things as we do. In a way, the desire to put profits over privacy is nothing new.
As far back as 1890, future Supreme Court Justice Louis Brandeis published an article in the Harvard Law Review, making the case for a “Right to Privacy” in the United States.
He warned: “Gossip is no longer the resource of the idle and of the vicious, but has become a trade.”
Today that trade has exploded into a data industrial complex. Our own information, from the everyday to the deeply personal, is being weaponized against us with military efficiency.
Every day, billions of dollars change hands and countless decisions are made on the basis of our likes and dislikes, our friends and families, our relationships and conversations, our wishes and fears, our hopes and dreams.
These scraps of data, each one harmless enough on its own, are carefully assembled, synthesized, traded and sold.
Taken to its extreme, this process creates an enduring digital profile and lets companies know you better than you may know yourself. Your profile is then run through algorithms that can serve up increasingly extreme content, pounding our harmless preferences into hardened convictions. If green is your favorite color, you may find yourself reading a lot of articles — or watching a lot of videos — about the insidious threat from people who like orange.
In the news almost every day, we bear witness to the harmful, even deadly, effects of these narrowed worldviews.
We shouldn’t sugarcoat the consequences. This is surveillance. And these stockpiles of personal data serve only to enrich the companies that collect them.
This should make us very uncomfortable. It should unsettle us. And it illustrates the importance of our shared work and the challenges still ahead of us.
Fortunately this year you’ve shown the world that good policy and political will can come together to protect the rights of everyone. We should celebrate the transformative work of the European institutions tasked with the successful implementation of the GDPR. We also celebrate the new steps taken, not only here in Europe, but around the world. In Singapore, Japan, Brazil, New Zealand and many more nations, regulators are asking tough questions and crafting effective reforms.
It is time for the rest of the world — including my home country — to follow your lead.
We at Apple are in full support of a comprehensive federal privacy law in the United States. There and everywhere, it should be rooted in four essential rights: First, the right to have personal data minimized. Companies should challenge themselves to de-identify customer data — or not to collect it in the first place. Second, the right to knowledge. Users should always know what data is being collected and what it is being collected for. This is the only way to empower users to decide what collection is legitimate and what isn’t. Anything less is a sham. Third, the right to access. Companies should recognize that data belongs to users, and we should all make it easy for users to get a copy of, correct and delete their personal data. And fourth, the right to security. Security is foundational to trust and all other privacy rights.
Now, there are those who would prefer I hadn’t said all of that. Some oppose any form of privacy legislation. Others will endorse reform in public, and then resist and undermine it behind closed doors.
They may say to you, “Our companies will never achieve technology’s true potential if they are constrained with privacy regulation.” But this notion isn’t just wrong, it is destructive.
Technology’s potential is, and always must be, rooted in the faith people have in it, in the optimism and creativity that it stirs in the hearts of individuals, in its promise and capacity to make the world a better place.
It’s time to face facts. We will never achieve technology’s true potential without the full faith and confidence of the people who use it.
At Apple, respect for privacy — and a healthy suspicion of authority — have always been in our bloodstream. Our first computers were built by misfits, tinkerers and rebels — not in a laboratory or a board room, but in a suburban garage. We introduced the Macintosh with a famous TV ad channeling George Orwell’s 1984 — a warning of what can happen when technology becomes a tool of power and loses touch with humanity.
And way back in 2010, Steve Jobs said in no uncertain terms: “Privacy means people know what they’re signing up for, in plain language, and repeatedly.”
It’s worth remembering the foresight and courage it took to make that statement. When we designed this device we knew it could put more personal data in your pocket than most of us keep in our homes. And there was enormous pressure on Steve and Apple to bend our values and to freely share this information. But we refused to compromise. In fact, we’ve only deepened our commitment in the decade since.
From hardware breakthroughs that encrypt fingerprints and faces securely — and only — on your device, to simple and powerful notifications that make clear to every user precisely what they’re sharing and when they are sharing it.
We aren’t absolutists, and we don’t claim to have all the answers. Instead, we always try to return to that simple question: What kind of world do we want to live in?
At every stage of the creative process, then and now, we engage in an open, honest and robust ethical debate about the products we make and the impact they will have. That’s just a part of our culture.
We don’t do it because we have to. We do it because we ought to. The values behind our products are as important to us as any feature.
We understand that the dangers are real — from cyber-criminals to rogue nation states. We’re not willing to leave our users to fend for themselves. And we’ve shown we’ll defend those principles when challenged.
Those values — that commitment to thoughtful debate and transparency — they’re only going to get more important. As progress speeds up, these things should continue to ground us and connect us, first and foremost, to the people we serve.
Artificial Intelligence is one area I think a lot about. Clearly it’s on the minds of many of my peers as well.
At its core, this technology promises to learn from people individually to benefit us all. Yet advancing AI by collecting huge personal profiles is laziness, not efficiency. For artificial intelligence to be truly smart, it must respect human values, including privacy.
If we get this wrong, the dangers are profound.
We can achieve both great artificial intelligence and great privacy standards. It’s not only a possibility, it is a responsibility.
In the pursuit of artificial intelligence, we should not sacrifice the humanity, creativity and ingenuity that define our human intelligence.
And at Apple, we never will.
In the mid-19th century, the great American writer Henry David Thoreau found himself so fed up with the pace and change of industrial society that he moved to a cabin in the woods by Walden Pond.
Call it the first digital cleanse.
Yet even there, where he hoped to find a bit of peace, he could hear a distant clatter and whistle of a steam engine passing by. “We do not ride on the railroad,” he said. “It rides upon us.”
Those of us who are fortunate enough to work in technology have an enormous responsibility.
It is not to please every grumpy Thoreau out there. That’s an unreasonable standard, and we’ll never meet it.
We are responsible, however, for recognizing that the devices we make and the platforms we build have real, lasting, even permanent effects on the individuals and communities who use them.
We must never stop asking ourselves, what kind of world do we want to live in?
The answer to that question must not be an afterthought, it should be our primary concern.
We at Apple can — and do — provide the very best to our users while treating their most personal data like the precious cargo that it is. And if we can do it, then everyone can do it.
Fortunately, we have your example before us.
Thank you for your work, for your commitment to the possibility of human-centered technology, and for your firm belief that our best days are still ahead of us.
Thank you very much.
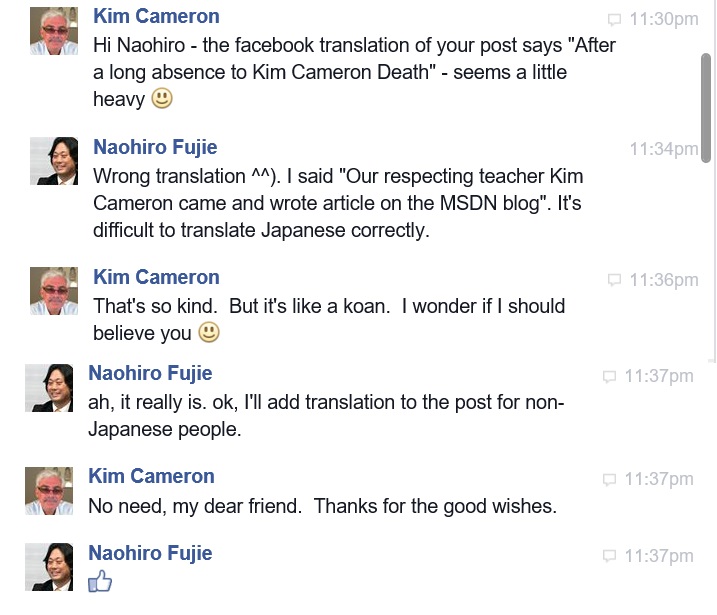
That this speech represents a really commendable watershed moment is best demonstrated by its low point: Tim’s “embellishment” of Apple’s stance towards privacy back in 2010.
For the record, the only error in the CSO article is that I actually took Microsoft to task for having broken the Laws of Identity while I worked at Microsoft. And the main reason I stayed at Microsoft is because they listened.
By the way, I’ve never admitted this before, but I was so peaved by Apple’s assertion that they could release my identifier and location to anyone they wanted, that I took my iPhone, which until then I had liked, put it on my driveway, and squished it into aluminum foil by driving over it several times.
In light of Tim Cook’s terrific speech, I think I will probably get one again. Thanks, Tim, for pressing that reset button.


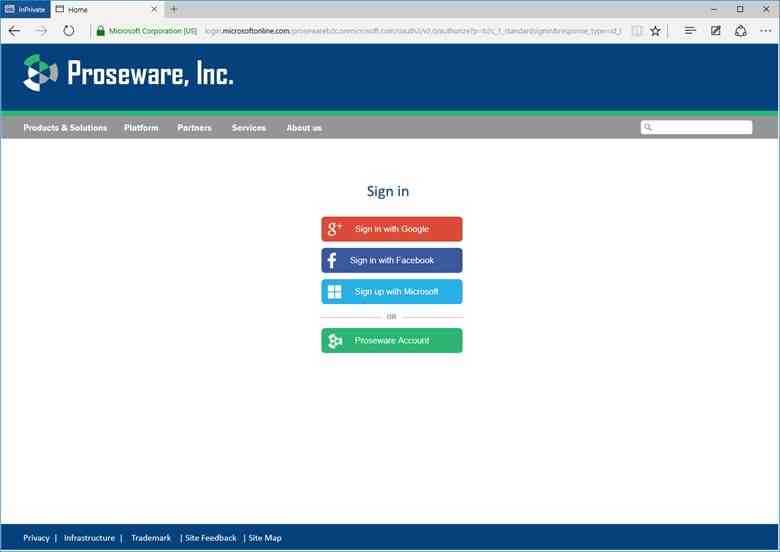
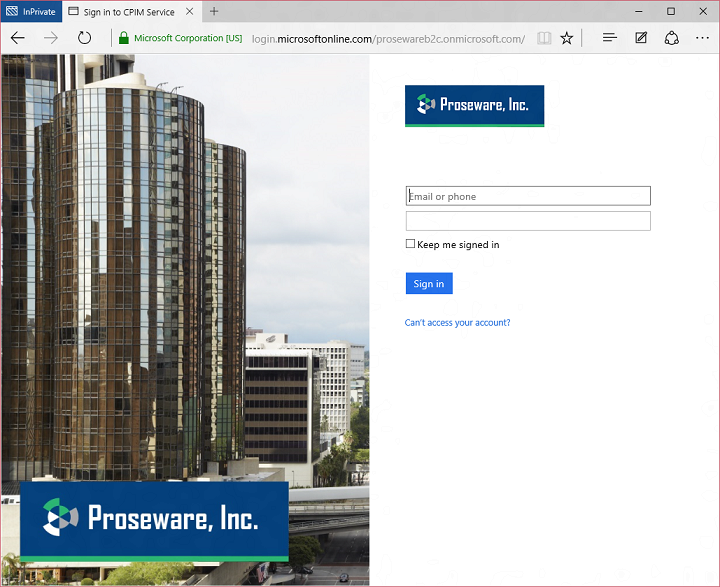
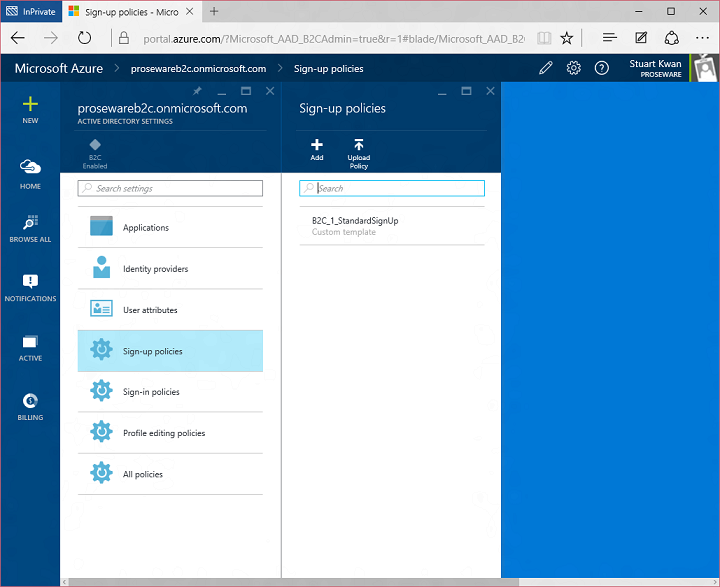
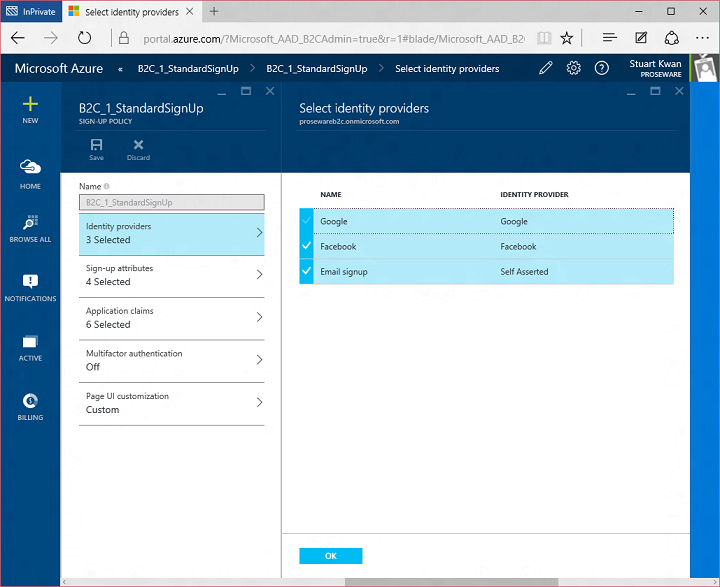
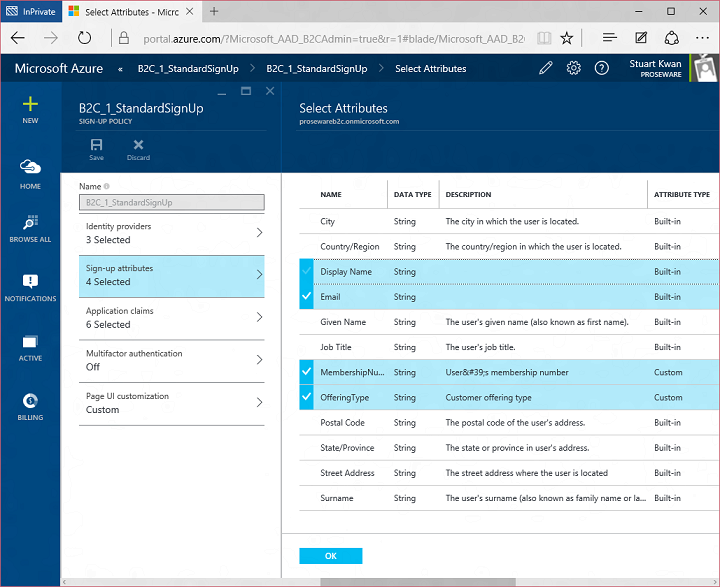
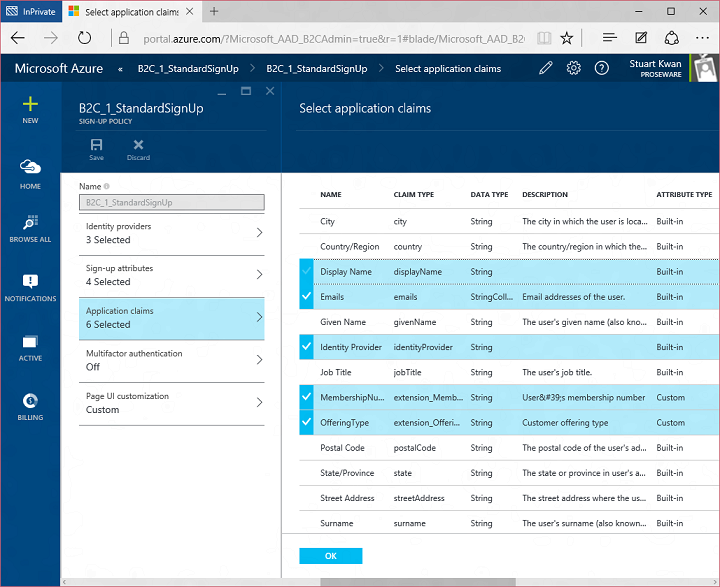
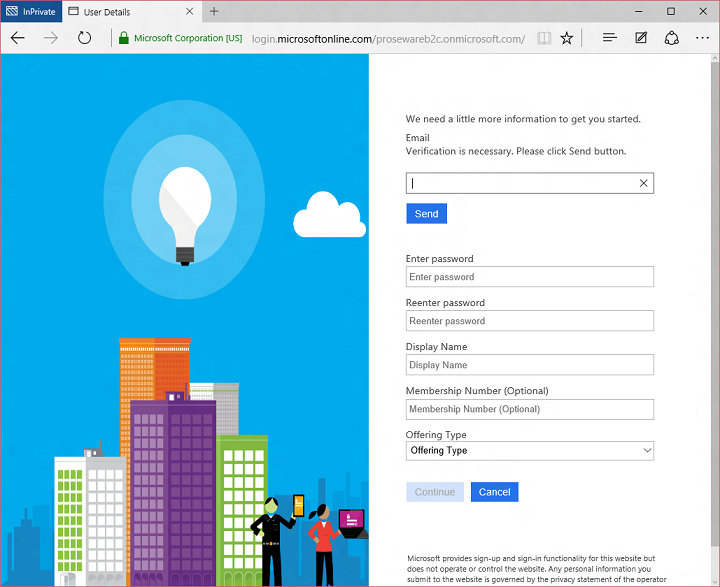
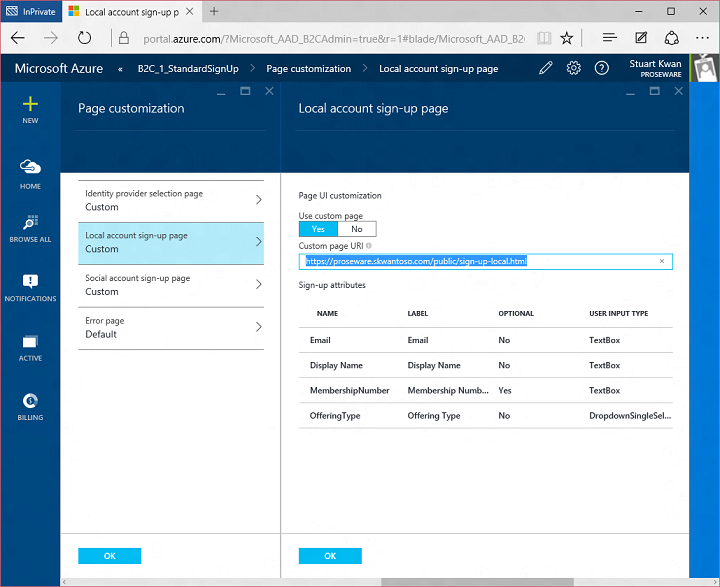
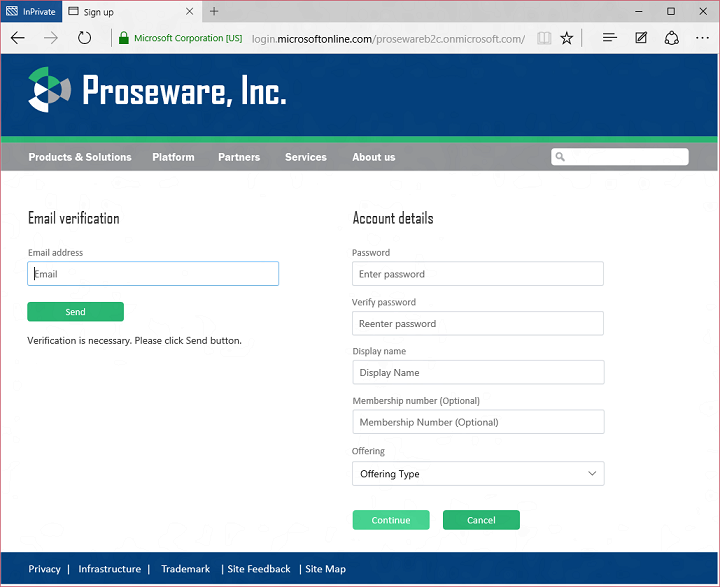
 Today I’d like to build on Stuart’s introduction by explaining why we saw a customizable, policy-based approach to B2C as being essential – and what it means for the rest of our identity architecture. This will help you understand how our B2C Basic offering, now in public preview, actually works. It will also provide insight into the capabilities of our upcoming B2C Premium offering, currently in private preview with Marquee customers. I think it will become evident that the combination of our Basic and Premium products will represent a substantial step forward for the industry. It means organizations of any size can handle all their different customer relationships, grow without limitation, gain exceptional control of user experience and still dramatically reduce risk, cost, and complexity.
Today I’d like to build on Stuart’s introduction by explaining why we saw a customizable, policy-based approach to B2C as being essential – and what it means for the rest of our identity architecture. This will help you understand how our B2C Basic offering, now in public preview, actually works. It will also provide insight into the capabilities of our upcoming B2C Premium offering, currently in private preview with Marquee customers. I think it will become evident that the combination of our Basic and Premium products will represent a substantial step forward for the industry. It means organizations of any size can handle all their different customer relationships, grow without limitation, gain exceptional control of user experience and still dramatically reduce risk, cost, and complexity.