First Microsoft's announcement with JanRain, SXIP and Verisign at RSA. Now news that AOL has launched an experimental system and announced it will support the next version of OpenID.
The world streams by at breakneck speed. We're getting some real momentum on this convergence thing. I hear the identity big bang coming towards us. Here's a fascinating post by panzerjohn at dev.aol.com.
Yesterday, I blogged about AOL's work-in-progress on OpenID. It generated a lot of positive commentary. I realized after reading the reactions that I buried the lead: There are now 63 million AOL/AIM OpenIDs. Anyone can get one by signing up for a free AIM account. This is cool.
To address Paul's concern in Please delete my aol OpenID: We definitely want the user to be in control of their online presence. At the moment, the OpenID URL at openid.aol.com redirects you off to an AIM Profile. That's not necessarily the long term experience, though I think it should be one of the default options. George Fletcher has pointed out that it would be even better if we could redirect people off to whatever page they wanted, as long as they could verify that they owned the page. My take is, if you don't actually use the OpenID URL, it doesn't really exist. The same way a Wiki page doesn't exist until you edit it. On the other hand, having people go in and kick the tires to uncover issues is exactly why we're talking about this. So let us know what you think.
Another important point is that you can point at the AOL OpenID service from any web page you own in order to turn its URL into an OpenID. The minimal requirements are basically that you have some AOL or AIM account, and that you add a couple of links to your document's HEAD:
link href=”https://api.screenname.aol.com/auth/openidServer” mce_href=”https://api.screenname.aol.com/auth/openidServer” rel=”openid.server”
link href=”http://openid.aol.com/screenname” mce_href=”http://openid.aol.com/screenname” rel=”openid.delegate”
We added this to our blogs product in a few minutes minutes and it's in beta now. You can also support YADIS discovery which gives additional capabilities. See Sam Ruby's OpenID for non SuperUsers for a good summary.
The detailed status from yesterday's post:
Every AOL/AIM user now has at least one OpenID URI, http://openid.aol.com/screenname.
This experimental OpenID 1.1 Provider service is available now and we are conducting compatibility tests.
We're working with OpenID relying parties to resolve compatibility issues.
Our blogging platform has enabled basic OpenID 1.1 in beta, so every beta blog URI is also a basic OpenID identifier. (No Yadis yet.)
We don't yet accept OpenID identities within our products as a relying party, but we're actively working on it. That roll-out is likely to be gradual.
We are tracking the OpenID 2.0 standardization effort and plan to support it after it becomes final.
(I should clarify that I really work in the social networking / community / profile / blogging groups at AOL rather than the identity group per se. You can look to see what I actually do on a day to day basis over at my personal blog.)
Jackson Shaw knows as much about identity management as anyone. I very much value his thinking. If that weren't enough, there is that irresistable love of life that sweeps everyone into his energy field. I think it comes through in his new blog:
No, it's not another French post from Jackson. Tonight I did something a bit different. I headed over to the Capital Hill Art Center in downtown Seattle to watch . There were 21 speakers scheduled including Scott Kveton the CEO of the folks behind . As you probably know, my buddy Kim Cameron is the man behind the curtain for Microsoft's CardSpace initiative ( I guess I should stop calling it an initiative – it is actually part of Vista now) and at the RSA conference Microsoft announced that CardSpace would be interoperable with OpenID.
I thought since Scott was going to present I might as well go over and see what all the hub-bub was about. The format of the evening was interesting in itself. Presenters had 5 minutes – only – to present their 20 slides! That's 15 seconds a slide. Scott was third presenter in the first volley of speakers. The first talk was from Matthew Maclaurin of Microsoft Research on Programming for Fun/Children/Hobbyists/Hackers. The second was from Elisabeth Freeman (Author in the Head First Series, Works at Disney Internet Group) on The Science Behind the Head First Books: or how to write a technical book that doesn’t put your readers to sleep. Then Scott was to speak.
First, I was shocked to walk into this “art space” that was packed to the rafters with people. Was I in the wrong place? Apparently not. On the website they stated the space would hold 400 people and it was jam packed. I had this vision of a few people sitting around some tables chatting. Not so! It was pretty cool; folksy; kinda out there but very engaging. Second, what was I going to get out of a 5 minute talk? Well, the speakers kind of had the pressure on them to make their points. The ones that I saw all got to the point quickly and they all engaged the with the audience, did their thing and got off.
Check out my photos on Picasa if you want to see the shots I took which included many from Scott's talk. So, what did I learn from Scott's talk?
OpenID is single sign-on for the web
Simple, light-weight, easy-to-use, open development process
Decentralized
Lots of companies are already using it or have pledged support
12-15M users have OpenIDs; 1000+ OpenID enabled sites
10-15 new OpenID sites added each day
7% growth every week in sites
Scott predicts that in 2007 there will be 100M users, 7,500 sites, big players adopt OpenID and that OpenID services emerge. Bold predictions but something that is viral, like OpenID has a shot at it.
I have to say I was impressed. Scott finished up with a call to action that included learning more about OpenID at openidenabled.com. I'm definitely heading over there to learn more.
Jackson just “gets” the potential for contagion into the enterprise – assuming we can use OpenID in the proper roles and with the right protections. Corroborates for me the possible “charging locomotive effect”. People shouldn't be caught looking the wrong way.
As for the numbers Scott threw out, I think they are very achievable.
To understand this discussion, start here and then follow the continuation links until you return to this posting. Click on the images below to see a larger and more readable version.
In the demo, as shown in the following screen shot, only the HelloWorld card is illuminated – all the other cards were “greyed out” as inappropriate:
This happened because in the Information Card login page, the “relying party” expressed a requirement that a HelloWorld card be presented. This was done by embedding “policy” in the “object tag” that tells the browser (and through it, CardSpace) what Information Cards will be accepted. To drill into this, let's look again at the login page:
Here's the HTML that created it:
You'll see that one of the PARAMs in the OBJECT tag is “tokenType”. It's set to a completely arbitrary value – one I made up to show you can do whatever you want – of http://kcameron11/identity/helloworldToken, Since I specified this specific token type, only Information Cards that support it will illuminate at selection time when you go to this web page. Further, the other PARAM specifies “requiredClaims”. Only Information Cards that support these values will be possible candidates.
These new documents are too low-level to be of interest to people working on the practical issues of deploying Information Cards on their Web sites.
But they may be of interest to students, researchers and the intrepid souls who really want to get their hands dirty and understand the nitty-gritty of the underlying technical elements.
The latest and most accurate version of “A Technical Reference for the Information Card Profile V1.0” is available for download here. In addition, I've posted a new version of “A Guide To Interoperating with the Information Card Profile V1.0” since it had a few grammatical errors and an inaccuracy in one of the examples – the URI of the self-issued IP claims was incorrect.
To understand this discussion, start here and then follow the continuation links. Click on any of the images below to see a larger and more readable version.
When you pressed the “Install” button on the “try it” page, you would have seen the normal “Open or Save” dialog:
If you then clicked “Open”, CardSpace would have brought you the standard “Reputation and Privacy” dialog, showing the certified details of the HelloWorld identity provider, and asking if you want to install its card:
Armed with your new card, you would have begun the “usage” demo by going to the HelloWorld information card login page:
Clicking on the InfoCard image to log in, CardSpace would have shown the “Relying Party Reputation and Privacy” page for Identityblog. (If you normally use InfoCards at Identityblog, you won't see it. In order to avoid “clickthrough syndrome”, it only shows up when you start a new relationship with a relying party.)
Once you approve starting the identity relationship, you are taken to your CardSpace card selector, and your HelloWorld card will be illuminated, since in this demo, the relying party has asked for that kind of card:
When you click on the card, you can preview what will be sent to the relying party should you opt to proceed. To get any information out of the HelloWorld identity provider, you need to authenticate to it. The first version of CardSpace supports four ways to do this (more in a later piece). This demo uses the simplest mechanism – entering a password within the protected CardSpace environment:
Now you'll have a chance to review the contents which will be sent from the identity provider to the relying party:
The contents include “favorite snack” – an attempt to show the elasticity of the contents. If you decide to proceed, the HelloWorld token is transfered to the relying party, which displays it verbatim:
For those who are multi-tasking as they read this, I'll show the token full size to make sure the format and contents are as clear as possible.
I don't want to get sidetracked into a discussion of the nuances the SAML protocol and token independence, but imagine readers will want me to share a comment by Scott Cantor – one of the principal creators of Shibboleth. He knows something about SAML too – since he was the editor of the Version 2.0 spec. He is responding to my recent post about why communications protocol, trust system and token payload must become three orthogonal axes:
SAML doesn’t have the problem Kim is referring to either. Both trust model and token format are out of scope of SAML protocol exchanges. The former is generally understood, but the token issue is the source of a lot of FUD, or in Kim’s case just misunderstanding SAML. This is largely SAML’s own fault, as the specs do not explain the issue well.
It is true that SAML protocols generally return assertions. What isn’t true is that a SAML assertion in and of itself is a security token. What turns a SAML assertion into such a token is the SubjectConfirmation construct inside it. That construct is extensible/open to any token type, proof mechanism, trust model, etc.
So the difference between SAML and WS-Trust is that SAML returns other tokens by bridging them from a SAML assertion so as to create a common baseline to work from, while WS-Trust returns the other tokens by themselves. This isn’t more or less functional, it’s simply a different design. I suppose you could say that it validates both of them, since they end up with the same answer in the end.
An obvious strategy for bridging SAML and OpenID is using an OpenID confirmation method. That would be one possible “simple†profile, although others are possible, and some have been discussed.
I'm not sure I really misunderstand SAML. I actually do understand that the SubjectConfirmation within SAML offers quite a bit of elasticity. But SAML does have a bunch of built-in assumptions within the Assertion that make it, well, SAML (Security Assertion Markup Language). These aren't always the assumptions you want to make. I'll share one of my own experiences with you.
CardSpace supports a mode of operation we call “non-auditing”. In this mode, the identity of the relying party is never conveyed to the identity provider.
The identity provider can still create assertions for the relying party, sign them, and send them back to CardSpace, which can in turn forward them to the relying party. If done properly, using a reasonable caching scheme, this provides a high degree of privacy, since the identity provider is blind to the usage of its tokens. For example, one could imagine a school system issuing my daughter a token that says she's under sixteen that she could use to get into protected chat rooms. In non-auditing mode the school system would not track which chat rooms she was visiting, and the chat room would only know she is of the correct age. This is certainly an increasingly important use case.
My first instinct was to use SAML Assertions as the means for creating this kind of non-audited assertion. But as Arun Nanda and I started our design we discovered that SAML – even SAML 2.0 – just wouldn't work for us.
In the specification (latest draft), section 2.3.3 says a SAML Assertion MUST have a unique ID. It must also have an IssueInstant. When that is the case, the identity provider can always collaborate with the relying party to do a search on the unique ID or IssueInstant, so the desired privacy characteristics dissipate.
Being a person of some deviousness who just wants to get things done, I said to Arun, “I know you won't like this, but I wonder if we couldn't just create an ID that would be the canonical ‘untraceable identifier’?” I hesitate to admit this and do so only to show I really was trying to get reuse.
But within a few seconds, Arun pointed out the following stipulation from section 1.3.4:
Any party that assigns an identifier MUST ensure that there is negligible probability that that party or any other party will accidentally assign the same identifier to a different data object.
I could have argued we weren't reassigning it “accidentally”, I suppose. But there you are. I needed a new “Assertion” type – by which I'm referring to the payload hard-wired into SAML.
It isn't that there is anything wrong with a SAML Assertion. The “ID” requirement and “IssueInstant” make total sense when your use case is centered primarily around avoiding replay attacks. But I had a different use case, and needed a different payload, one incompatible with the SAML protocol. And going forward, I won't be the last to operate outside of the assumptions of any given payload, no matter how clever.
I have looked deeply at SAML, but am convinced that protocol, payload (call it assertion type or token type, I don't care) and trust fabric need all to be orthogonal. SAML was a great step forward after PKI because it disentangled trust framework from the Assertion/Protocol pairing (in PKI they had all been mixed up in a huge ball of string). But I like WS-Trust because it completes the process, and gets us to what I think is a cleaner architecture.
In spite of all this, I totally buy Scott's uberpoint that for a number of common use cases SAML and WS-Fed (meaning WS-Trust in http redirection mode) are not more or less functional, but simply a different design.
In a posting called “OpenID? Huh?“, Francis Shanahan, whose job it is to worry about high value financial transactions and strong assertions about molecular identity, wonders why OpenID is nothing more than a reinvention of the WS wheel.
“I don't understand OpenID [LINK]. I'm sorry. I've tried to understand it but I just don't get it.
“The spec is confusing but thankfully Phil Windley has translated it into a diagram for us mere mortals [LINK].
“The idea of OpenID is to provide “an open, decentralized, free framework for user-centric digital identity.”
“And here's how the flow works (at least one of the scenarios). Note I've taken Phil's explanation and augmented it with my own understanding:
User is presented with OpenID login form by the Consumer
User responds with the URL that represents their OpenID (for example “FrancisShanahan.myIDServer.com”). Now the Consumer needs to determine if I actually “own” the URL I've specified.
Consumer canonicalizes the OpenID URL and uses the canonical version to request (GET) a document from the Identity Server.
Identity Server returns the HTML document named by the OpenID URL
Consumer inspects the HTML document header for
tags with the attribute rel set to openid.server and, optionally, openid.delegate. The Consumer uses the values in these tags to construct a URL with mode checkid_setup for the Identity Server and redirects the User Agent. {fs: Said differently, the consumer directs the user to login at their ID server.} This checkid_setup URL encodes, among other things, a URL to return to in case of success and one to return to in the case of failure or cancellation of the request
The OpenID Server returns a login screen.
User sends (POST) a login ID and password to OpenID Server. {fs: I assume you can authenticate how ever your OpenID server likes}
OpenID Server returns a trust form asking the User if they want to trust Consumer (identified by URL) with their Identity
User POSTs response to OpenID Server.
User is redirected to either the success URL or the failure URL returned in (5) depending on the User response
Consumer returns appropriate page to User depending on the action encoded in the URL in (10)
“Ok, makes sense but there's an obvious problem as Kim Cameron correctly points out in this post [LINK].
“If you assume the Consumer is evil, they can take the openID URL from step 2 and instead of directing the user to that legitimate URL, they can substitute it with their own faker site. This site'll look EXACTLY like the one the user's expecting. The user unwittingly enters their credentials and the scenario continues as normal. The user's never aware that they were phished.
“Clearly there's a piece missing that Kim claims can be provided by the CardSpace ID selector. By integrating OpenID with CardSpace you can avoid malicious redirections and phishing in the protocol. But then what've you actually achieved? You've just re-invented the WS-* wheel all over again using redirects and a browser? So what's the point?
“I don't get it but this is dark mojo and I'm probably missing something somewhere.”
Let me clarify what really happens. Let's go back to step (2) above. We know Francis by his blog URL – http://www.francisshanahan.com. So if he was going to leave comments on my blog, he would most likely use his own blog URL as his OpenID.
Note that his blog URL isn't an identity server. So in step (3), the consumer doesn't contact an identity server – it requests and gets Francis’ actual web page (or, at least, its header). As explained in step (5), the header contains a “link” element telling the consumer who to trust as the identity provider for this page.
Now, in steps (5) through (10), the user is redirected to the identity server, enters his credentials, and picks up a coupon that he gives back to the consumer after another redirect. Behind the scenes, the consumer then sends the coupon back to the identity provider (using a backchannel) to see if it is valid. (There is a potential optimization that can be used here involving exchange of a key – but it is only an optimization).
So let's think about this. Where is the root of trust? In conventional systems like PKI or SAML or Kerberos, the root of trust is the identity provider. I trust the identity provider to say something about the subject. How do I know I'm hearing from the legitimate identity provider? I have some kind of cryptographic key. The relevant key distribution has a cost – such as that involved in obtaining or issuing public key certificates, or registering with a Key Distribution Center.
But in OpenID, the root of trust is the OpenID URL itself. What you see is what you get. In the example above, I trust Francis’ web page since it represents his thinking and is under his control. His web page delegates to his OpenID identity provider (OP) through the link mechanism in (5). Because of that, I trust his identity provider to speak on behalf of his web page. How do I know I am looking at his web page or talking to his identity provider? By calling them up on DNS.
I'm delving into the details here because I think this is what gives OpenID its legs. It is as strong, and as weak, as DNS. In other words, it is great for transactions that won't attract criminal attack, and terrible for those that will.
This now brings us face to face with the essence of the metasystem idea. We don't live in a one-size-fits-all world. Identity involves different – and even contradictory – use cases. Rather than some monolithic answer, we need a metasystem in which the cost (in complexity or money) of using identity is proportional to the value of the asset being protected. OpenID cannot replace crypto-based approaches in which there are trusted authorities rather than trusted web pages. But it can add a whole new dimension, and bring the “long tail” of web sites into the identity fabric.
The way I see it, there is a spectrum with DNS-based technology at one end and hardware-backed crypto technology at the other. If we can get this continuum structured into a metasystem, the dichotomy between RESTful and Web Services approaches can be changed from a religious war to simple selection of the right tool for the right task. That's why I want to see OpenID as an integral part of a metasystem providing a common experience while respecting the economics of identity.
This having been said, Francis is right for asking whether we've “just re-invented the WS-* wheel all over again using redirects and a browser?”. While I think it is known I'm a strong supporter of SAML as a step forward for identity, I've been an equally vocal advocate of separating communications protocol, trust, and token payloads. OpenID has a different token payload and trust system than SAML, but if the three axes had been properly disentangled, you could imagine OpenID as a very simple SAML profile. Because of the entanglement, that can't be the case.
WS-Federation (possibly misnamed…) doesn't have this problem. It can carry any token, and use any trust framework. OpenID would work inside the WS-Federation protocol patterns, and would be able to retain its payload and trust structure. So could SAML for that matter. So there is the “theoretical possibility” of merging all these things. Will it happen? Someone would have to pass out large quantities of pain killers, but there is a possible future in which, over time, they converge.
One of the most important things about the Information Card paradigm is that the cards are just ways for the user to represent and employ digital identities (meaning sets of claims about a subject).
The paradigm doesn't say anything about what those claims look like or how they are encoded. Nor does it say anything about the cryptographic (or other) mechanisms used to validate the claims.
You can really look at the InfoCard technology as just being
a way that a relying party can ask for claims of “some kind”;
a safe environment through which the user can understand what's happening; and
the tubing through which a related payload is transfered from the user-approved identity provider to the relying party. The goal is to satisfy the necessary claim requirements.
If you have looked at other technologies for exchanging claims (they not called that, but are at heart the same thing), you will see this system disentangles the communication protocol, the trust framework and the payload formats, whereas previous systems conflated them. Because there are now three independent axes, the trust frameworks and payloads can evolve without destabilizing anything.
CardSpace “comes with” a “simple self-asserted identity provider” that uses the SAML 1.1 token format. But we just did that to “bootstrap” the system. You could just as well send SAML 2.0 tokens through the tubing. In fact, people who have followed the Laws of Identity and Identity Metasystem discussions know that the fifth law of identity refers to a pluralism of operators and technologies. When speaking I've talked about why different underlying identity technologies make sense, and compared this pluralism to the plurality of transport mechanisms underlying TCP/IP. I've spoken about the need to be “token agnostic” – and to be ready for new token formats that can use the same “tubing”.
There have been some who have rejected the open “meta” model in favor of just settling on tokens in the “concept de jour”. They urge us to forget about all these subtleties and just adopt SAML, or PKI, or whatever else meets someone's use cases. But the sudden rise of OpenID shows exactly why we need a token-agnostic system. OpenID has great use cases that we should all recognize as important. And because of the new metasystem architecture, OpenID payloads can be selected and conveyed safely through the Information Card mechanisms just as well as anything else. To me it is amazing that the identity metasystem idea isn't more than a couple of years old and yet we already have an impressive new identity technology arising. It provides an important example of why an elastic system like CardSpace is architecturally right.
It's sometimes hard to explain how all this works under the hood. So I've decided to give a tutorial about “HelloWorld” cards. They don't follow any format previously known to man – or even woman. They're just someting made up to show elasticity. But I'm hoping that when you understand how the HelloWorld cards work, it will help you see the tremendous possibilities in the metasystem model.
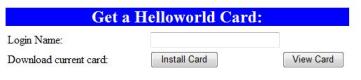
The best way to follow this tutorial is to actually try things out. If you want to participate, install CardSpace on XP or use Vista, download a HelloWorld Card and kick the tires. (I'm checking now to see if other selector implementations will support this. If not, I know that compatibility is certainly the intention on everyones’ part).
The HelloWord card is just metadata for getting to a “helloworld” identity server. In upcoming posts I'll explain how all this works in a way that I hope will make the technology very clear. I'll also make the source code available. An interesting note here: the identity server is just a few hundred lines of code.
To try it out, enter a login name and download a card (if you don't enter a name, you won't get an error message right now but the demonstration won't work later). Once you have your card, click on the InfoCard icon here. You'll see how the HelloWorld token is transferred to the relying party web site.
This card uses passwords for authentication to the HelloWorld identity provider, and any password will do.
I'd like to share this interesting comment by Francis Shanahan, who works on identity from the vantage point of Citi:
“Your blog talks about “Cardspace enabling Apache”. Regarding the language in the post, I know I'm being picky here but…
“Wouldn't it be more correct to say “XML Tokens as an additional authentication…” rather than “…Information Cards as an additional authentication mechanism…” since I can use Kerberos or SAML tokens with Cardspace over WS-Fed.
“Wouldn't it be more correct to say “token enable” rather than “Cardspace enable”? I don't need to use the Cardspace selector with a WS-Trust enabled site.
“Wouldn't it be more correct to say “The whole identity token processing can…” rather than “The whole cardspace processing can…” and so on. CardSpace is just the ID selector used to faciliate the token exchange.
“Just don't want to confuse folks thinking there's a Cardspace specific token.”
First I'll say that technically speaking I think you make good points, and I'll try to be as careful as I can to bring out these ideas.
Then, since pointing the finger at someone else is so fashionable, I'll say I was quoting what another company said it was doing. (That, in itself, is interesting.)
But most important, I'll argue that the simplification of our current ideas into “iconic” notions is inevitable, and worthwhile, even though subtleties will be lost. So we have to achieve a balance between the irreconcilables of breadth and accuracy.
I'll start with an analogy – the analogy to file and folder icons. Computer scientists know files are potentially complex mappings of streams of bits onto blocks of storage. They know folders are doubly linked lists of pointers to these streams of bits. But if they're smart, they keep all of this to themselves – even when they're with other computer scientists and the door is closed. If we told people about the inner workings of file systems, we'd drive them crazy. In fact, they still wouldn't know how to manage documents or pictures or music.
Instead, people have gotten used to little pictures of files, and drag them from one “folder” to another – or even “onto” their mp3 players. Our official help files say things like “Double click on the document to open it”. We conveniently overlook the fact that the document exists as magnetic fields on the hard disk and you can't double click them.
There is a dualism between the science of the thing and the way we conceive of it in usage, just as there is in all aspects of reality.
When we invent new technologies, we start from the science, and it's really hard to explain what one is doing. It takes months or even years to develop an “elevator pitch” – the ten second description of what you've done that makes it seem worth doing. But that doesn't actually matter much, assuming you get funding. What matters is the way the idea eventually enters mainstream consciousness.
It is inevitable that marketers will talk about products (CardSpace, Higgins, etc) rather than technology.
While people will “get” that something is being transferred when you authenticate or authorize, I suspect they'll always see the visual image as being the identity itself, with few understanding it as “a means to manage the metadata enabling connectivity between identity providers and relying parties”.
I think protocols like WS-Federation and WS-Trust will be more or less invisible except to backbone engineers.
Once we get an Information Card icon out there and people start to use it, I think people will take it as meaning “Information Cards accepted here” – and that, in their minds, will be synonymous with CardSpace or whatever Information Card selector they run on their devices. They'll realize that some sites want some cards and other sites want others, but will never think about token types.
So my reading is that Ping, which developed the Apache product being referred to, is already thinking about how to present a message that begins to deal with taking Information Cards to a wider audience. Not out of the technology ghetto yet, but to a wider audience within the very busy technology community. It would be interesting to hear what Andre Durand has to say about this.
be user-friendly, i.e. it should pass the mother-in-law test; and
work on the web platform without special software or browser plugin
“So, why is this suddenly a problem?
“Not really, phishing is a perennial problem on the Internet that researchers and developers have been trying to solve for many years now. OpenID just accentuates it because RPs are unregulated. You don’t need any agreement with any OP, essentially anyone can set up a web site and put the OpenID login button. If OpenID takes off, RP sites will grow like ’shrooms and user will get used to the idea that if they see the OpenID logo, they can type their URL to login. This only makes it harder for users to discern the good RPs from the bad ones.”
Actually, the problem is worse than the one we currently face. We are not just dealing with “the perennial problem”. If you use one OpenID account to go to two hundred sites, the thief who steals your OpenID credentials gains access to any of the 200 sites. That's new.
“This is really a social problem, and not a fault of the OpenID protocol. Users need only to trust their OP, and not the RPs that they interact with. If a rogue RP sends you to a page the poses as your OP but the URL doesn’t match your OP’s, you bail out. Doesn’t that sound simple? Well, the cold hard fact is that phishing works and there is research1 to prove that people get tricked very easily.”
Dready's right about the research. But rather than calling it a “social problem” I'd call it a “social engineering attack”. Further, there is a protocol problem. The protocol is based on telling the RP where the OP is located – such that an evil site can automate a “man in the middle attack”. Some other protocols, including the one used by CardSpace, do NOT have this problem. That's why combining CardSpace and OpenID is useful.
“Numerous ideas to mitigate phishing attacks have been floating around the OpenID list and on the OpenID mini-blogsphere. Ben Laurie argues for a client-side solution:
‘Authentication on the web is broken, and has been for a long time. The OpenID fanboys want OpenID to work on any old platform using only standard software, and so therefore are doomed to live in the world of broken authentication. This is fine if what you protect with your OpenID is worthless, but it seems clear that these types of protocol are going to be used to authenticate for things of value.
…
'This is the root of the problem: if you want to protect anything of value, you have to do better than existing Web solutions. You need better client-side software.’
“The picture is not so sunny, however, because most users:
won’t know / bother to install specialized plug-in or upgrade their browsers unless they’re forced to
won’t know the difference between citibank.com/signon and citibank.com-banking-foobar.com
“And even if they installed those anti-phishing toolbars and what not, they still fall for it!
“While I can’t decipher the wirings of the mums-and-dads who fall prey for phishing attacks, I know that I get lazy sometimes and just don’t bother. Then I remember this little trick that Firefox introduced to ensure that users get the warning before installing extensions — Introduce a delay in the dialog box before it can be dismissed. That sort of worked for me, at least for that 5 seconds I can’t click so I might as well read a little.” (Code follows here…)
This may help Dready and in that sense it may be a welcome finger in the dike. But as OpenID becomes successful and is used for sites of value, this kind of solution clearly won't stand up to attack or scale to embrace the population.
People really need to think about what it will mean to actually have “single signon”, rather than just talk about it.
You cannot overestimate the value of your single signon credentials, or the extent to which they will attract attack.
I don't think browser-based solutions will do anything for us long term – the whole point of browsers is to make it easy to introduce cool new behaviors and empower the RP to give the user great experience. They are vulnerable because they put the RP in control – by design.
This doesn't mean plugins can't play a role in getting us to our destination. But ultimately, you need defense in depth, many layers of defense. If we think of the browser as a “broadband communications channel” inundating the user with information, we also need a “narrowband communications channel” honed to protection of the user. The CardSpace work represents an attempt to create this.