
Further to Dave Kearn's article, here is the complete text of Paul Masden's comment:
Kim Cameron introduces a nice diagram into his series exploring linkability & correlation in different identity systems.
Kim categorizes correlation as either ‘IP sees all’, ‘RP/RP collusion’, or ‘RP/IP collusion’, depending on which two entities can ‘talk’ about the user.
A meaningful distinction for RP/RP collusion that Kim omits (at least in the diagram and in his discussion of X.509) is ‘temporal self-correlation’, i.e. that in which the same RP is able to correlate the same user's visits occurring over time.
Were an IDP to use transient (as opposed to persistent pseudonymous) identifiers within a SAML assertion each time it asserted to a RP, then not only would RP's be unable to collude with each other (based on that identifier), they'd be unable to collude with themselves (the past or future themselves).
I was working on a diagram comparable to Kim's, but got lost in the additional axis for representing time (e.g. ‘what the provider knows and when they learned it’ when considering collusion potential).
Separately, Kim will surely acknowledge at some point (or already has) that these identity systems, with their varying degrees of inhibiting correlation & subsequent collusion, will all be deployed in an environment that, by default, does not support the same degree of obfuscation. Not to say that designing identity systems to inhibit correlation isn't important & valuable for privacy, just that there is little point in deploying such a system without addressing the other vulnerabilities (like a masked bank robber writing his ‘hand over the money’ note on a monogrammed pad).
First, I love Paul's comment that he “got lost in the additional axis”, since there are many potential axes – some of which have taken me to the steps of purgatory. Perhaps we can collect them into a joint set of diagrams since the various axes are interesting in different ways.
Second, I want everyone to understand that I do not see correlation as being something which is in itself bad. It depends on the context, on what we are trying to achieve. When writing my blog, I want everyone to know it is “me again”, for better or for worse. But as I always say, I would like to be able to use my search engine and read my newspaper without fear that some profile of me, the real-world Kim Cameron, would be assembled and shared.
The one statement Paul makes that I don't agree with is this:
Were an IDP to use transient (as opposed to persistent pseudonymous) identifiers within a SAML assertion each time it asserted to a RP, then not only would RP's be unable to collude with each other (based on that identifier), they'd be unable to collude with themselves (the past or future themselves).
I've been through this thinking myself.
Suppose we got rid of the user identifier completely, and just kept the assertion ID that identifies a given SAML token (must be unique across time and space – totally transient). If the relying party received such a token and colluded with the identity provider, the assertionID could be used to tie the profile at the relying party to the person who authenticated and got the token in the first place. So it doesn't really prevent linking once you try to handle the problem of collusion.
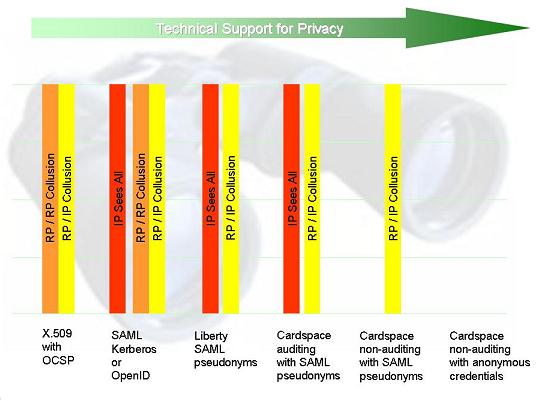
 What is good about X.509 is that if a relying party does not collude, the CA has no visibility onto the fact that a given user has visited it (we will see that in some other systems such visibility is unavoidable). But a relying party could at any point decide to collude with the CA (assuming the CA actually accepts such information, which may be a breach of policy). This might result in the transfer of information in either direction beyond that contained in the certificate itself.
What is good about X.509 is that if a relying party does not collude, the CA has no visibility onto the fact that a given user has visited it (we will see that in some other systems such visibility is unavoidable). But a relying party could at any point decide to collude with the CA (assuming the CA actually accepts such information, which may be a breach of policy). This might result in the transfer of information in either direction beyond that contained in the certificate itself.