Gunnar Peterson recently showed me a posting by Andy Jaquith (securitymetrics.org and JSPWiki) that combines coding, wiki, identity, Cardspace, cybervandals, and OpenID all into one post – a pretty interesting set of memes. Like me, he finally actually shut off anonymous commentary because he couldn't stand the spam workload, and is looking for answers:
Last week's shutoff of this website's self-registration system was something I did with deep misgivings. I've always been a fan of keeping the Web as open as possible. I cannot stand soul-sucking, personally invasive registration processes like the New York Times website. However, my experience with a particularly persistent Italian vandal was instructive, and it got me thinking about the relationship between accountability and identity.
Some background. When you self-register on securitymetrics.org you supply a desired “wiki name”, a full name, a desired login id, and optionally a e-mail address for password resets. We require the identifying information to associate specific activities (page edits, attachment uploads, login/log out events) with particular members. We do not verify the information, and we trust that the user is telling truth. Our Italian vandal decided to abuse our trust in him by attaching pr0n links to the front page. Cute.
The software we use here on securitymetrics.org has decent audit logs. It was a simple matter of identifying the offending user account. I know which user put the porn spam on the website, and I know when he did it. I also know when he logged in, what IP address he came from, and what he claimed his “real” name was. But although I've got a decent amount of forensic information available to me, what I don't have any idea of whether the person who did it supplied real information when he registered.
And therein lies the paradox. I don't want to keep personal information about members — but at the same time, I want to have some degree of assurance that people who choose to become members are real people who have serious intent. But there's no way to get any level of assurance about intent. After alll, as the New Yorker cartoon aptly put it, on the Internet no-one knows if you're a dog. Or just a jackass.
During the holiday break, I did a bit of thinking and exploration about how to address (note I do not say “solve”) issues of identity and accountability, in the context of website registration. Because I am a co-author of the software we use to run this website (JSPWiki), I have a fair amount of freedom in coming up with possible enhancements.
One obvious way to address self-registration identity issue is to introduce a vetting system into the registration process. That is, when someone registers, it triggers a little workflow that requires me to do some investigation on the person. I already do this for the mailing list, so it would be a logical extension to do it for the wiki, too. This would solve the identity issue — successfully vetting someone would enable the administrator to have much higher confidence in their identity claims, albeit with some sacrifice
There's just one problem with this — I hate vetting people. It takes time to do, and I am always far, far behind.
A second approach is to not do anything special for registration, but moderate page changes. This, too, requires workflow. On the JSPWiki developer mailing lists, we've been discussing this option quite a bit, in combination with blacklists and anti-spam heuristics. This would help solve the accountability problem.
A third approach would be to accept third-party identities that you have a reasonable level of assurance in. Classic PKI (digital certificates) are a good example of third-party identities that you can inspect and choose to trust or not. But client-side digital certificates have deployment shortcomings. Very few people use them.
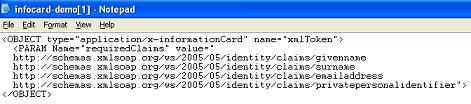
A promising alternative to client-side certificates is the new breed of digital identity architectures, many of which do not require a huge, monolithic corporate infrastructure to issue. I'm thinking mostly of OpenID and Microsoft's CardSpace specs. I really like what Kim Cameron has done with CardSpace; it takes a lot of the things that I like about Apple's Keychain (self-management, portability, simple user metaphors, ease-of-use) and applies it specifically to the issue of identity. CardSpace‘s InfoCards (I have always felt they should be called IdentityCards) are kind of like credit cards in your wallet. When you want to express a claim about your identity, you pick a card (any card!) and present it to the person who's asking.
What's nice about InfoCards is that, in theory, these are things you can create for yourself at a registrar (identity provider) of your choice. InfoCards also have good privacy controls — if you don't want a relying party (e.g., securitymetrics.org) to see your e-mail identity attribute, you don't have to release that information.
So, InfoCards have promise. But they use the WS-* XML standards for communication (think: big, hairy, complicated), and they require a client-side supplicant that allows users to navigate their InfoCards and present them when asked. It's nice to see that there's a Firefox InfoCard client, but there isn't one for Safari, and older versions of Windows are still left out in the cold. CardSpace will make its mark in time, but it is still early, methinks.
OpenID holds more promise for me. There are loads more implementations available (and several choices for Java libraries), and the mechanism that identity providers use to communicate with relying parties is simple and comprehensible by humans. It doesn't require special software because it relies on HTTP redirects to work. And best of all, the thing the identity is based on is something “my kind of people” all have: a website URL. Identity, essentially, boils down to an assertion of ownership over a URL. I like this because it's something I can verify easily. And by visiting your website, I can usually tell whether the person who owns that URL is my kind of people.
OpenID is cool. I got far enough into the evaluation process to do some reasonably serious interoperability testing with the SXIP and JanRain libraries. I mocked up a web server and got it to sucessfully accept identities from the Technorati and VeriSign OpenID services. But I hit a few snags.
Recall that the point of all of this fooling around is to figure out a way to balance privacy and authenticity. By “privacy”, I mean that I do not want to ask users to disgorge too much personal information to me when they register. And correspondingly, I do not want the custodial obligation of having to store and safeguard any information they give me. The ideal implementation, therefore, would accept an OpenID identity when presented, dyamically collect the attributes we want (really, just the full name and websute URL) and pull them into our in-memory session, and flush them at the end of the session. In other words, the integrity of the attributes presented, combined with transience yields privacy. It's kind of like the front-desk guard I used to see when I consulted to the Massachussetts Department of Mental Health. He was a rehabilitated patient, but his years of illness and heavy treatment left him with no memory for faces at all. Despite the fact I'd visited DMH on dozens of occasions, every time I signed in he would ask “Have you been here before? Do you know where you are going?” Put another way, integrity of identity + dynamic attribute exchange protocols + enforced amnesia = privacy.
By “authenticity” I mean having reasonable assurance that the person on my website is not just who they say they are, but that I can also get some idea about their intentions (or what they might have been). OpenID meets both of these criteria… if I want to know something more about the person registering or posting on my website, I can just go and check ’em out by visiting their URL.
But, in my experiments I found that the attribute-exchange process needs work… I could not get VeriSign's or Technorati's identity provider to release to my relying website the attributes I wanted, namely my identity's full name and e-mail addresses. I determined that this was because neither of these identity providers support what the OpenID people call the “Simple Registration” profile aka SREG.
More on this later. Needless to say, I am encouraged by my progress so far. And regardless of the outcome of my investigations into InfoCard and OpenID, my JSPWiki workflow library development continues at a torrid pace.
Bottom line: once we have a decent workflow system in place, I'll open registrations back up. And longer term, we will have more some open identity system choices.
Hmmm. Interesting thoughts that I want to explore more over the next while.
Before I get to the nitty-gritty, please note that Cardspace and InfoCards do NOT require a client-side wiki or web site to use WS-* protocols.
The system supports WS-*, which gives it the ability to handle upper-end scenarios, but doesn't require it and can operate in a RESTful mode!
So the actual effort required to implement the client side is on the same order of magnitude as for OpenID. But I agree there are not very many open-source options out there for doing this yet – requiring more creativity on the part of the implementor. I'm trying to help with this.
It's also true that InfoCards require client software (although there are ways around this if someone is enterprising: you could build an infocard selector that “lives in the cloud”).
But the advantages of InfoCard speak clearly too. Andy Jaquist would find that release of user information is built right in, and that “what you see is what you get” – user control. Further, the model doesn't expose the user to the risk that personal information will become public by being posted on the web. This makes it useful in a number of applications which OpenID can't handle without a lot of complexity.
But what's the core issue?
InfoCards change the current model in which the user can be controlled by an evil site. OpenID doesn't.
if a user ends up at an evil site today, it can pose as a good site known to the user by scooping the good site's skin so the user is fooled into entering her username and passord.
But think of what we unleash with OpenID…
It's way easier for the evil site to scoop the skin of a user's OpenID service because – are you ready? – the user helps out by entering her honeypot's URL!
By playing back her OpenID skin the evil site can trick the user into revealing her creds. But these are magic creds, the keys to her whole kingdom! The result is a world more perilous than the one we live in now.
If that isn't enough, evil doers armed with identifiers and ill-gotten creds can then crawl the web to see where the URL they have absconded with is in play, and break into those locations too.
The attacks on OpenID all lend themselves to automation…
One can say all this doesn't matter because these are low-value identities, but I think it is a question of setting off on the wrong foot unless we build the evolution of OpenID into it.
It will really be a shame if all the interest in new identity technology leads to security breaches worse than those that currently exist, and brings about a further demoralization of the user.
I'd like to see OpenID and InfoCard technologies come together more. I'll be presenting a plan for that over the next little while.

 If you haven't read Jim Harper's book, Identity Crisis: How Identification Is Overused and Missunderstood I urge you to do so as soon as you can.
If you haven't read Jim Harper's book, Identity Crisis: How Identification Is Overused and Missunderstood I urge you to do so as soon as you can. In the case described by Pat, the site really does use a “registration” model like the one from BestBuy shown here.
In the case described by Pat, the site really does use a “registration” model like the one from BestBuy shown here.