
We know how the web feeds itself in a chain reaction powered by the assembly and location of information. We love it. Bringing information together that was previously compartmentalized has made it far easier to find out what is happening and avoid thinking narrowly. In some cases it has even changed the fundamentals of how we work and interact. The blogosphere identity conversation is an example of this. We are able to learn from each other across the industry and adjust to evolving trends in a fluid way, rather than “projecting” what other peoples’ thinking and motivations might be. In this sense the content of what we are doing is related to the medium through which we do it.
Information accumulates power by being put into proximity and aggregated. This even appears to be an inherent property of information itself. Of course information can't effect its own aggregation, but easily finds hosts who are motivated to do so: businesses, governments, researchers, industries, libraries, data centers – and the indefatigable search engine.
Some forms of aggregation involve breaking down the separation between domains of facts. Facts are initially discerned within a context. But as contexts flow together and merge , the facts are visible from new perspectives. We can think of them as “views”.
Information trends and digital identity
How does this fundamental tendency of information to reorganize itself relate to digital identity?
This is clearly a complicated question. But it is perhaps one of the most important questions of our time – one that needs to come to the attention of students, academics, policy makers, legislators, and through them, the general public. The answer will affect everyone.
It is hard to clearly explain and discuss trends that are so infrastructural. Those of us working on these issues have concepts that apply, but the concepts don't really have satisfactory names, and just aren't crisp enough. We aren't ready for a wider conversation about the things we have seen.
Recently I've been trying to organize my own thinking about this through a grid expressing, on one axis, the tendency of context to merge; and, on the other, the spectrum of data visibility:
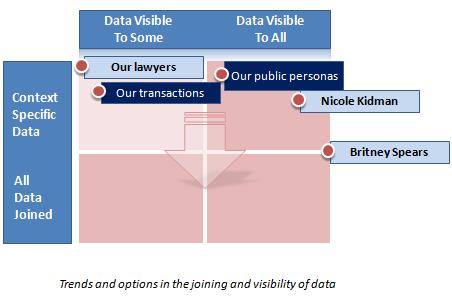
The spectrum of visibility extends from a single individual on the left to everyone in the society on the right [if reading a text feed please check the graphic – Kim].
The spectrum of contextual separation extends from complete separation of information by context at the top, to complete joining of data across contexts at the bottom.
I've represented the tendency of information to aggregate as the arrow leading from separation to full join, and this should be considered a dynamic tendency of the system.
Where do we fit in this picture?
Now lets set up a few markers from which we can calibrate this field. For example, let's take what I've labelled “Today's public personas”. I'm talking about what we reveal about ourselves in the public realm. Because it's public, it's on the “Visible to all” part of the spectrum. Yet for most of us, it is a relatively narrow set of information that is revealed – our names, property we own, aspects of our professional lives. Thus our public personas remain relatively contextual.
You can imagine variants on this – for example a show-business personality who might be situated further to the right than the “public persona”, being known by more people. Further, additional aspects of such a person's life might be known, which would be represented by moving down towards the bottom of the quadrant (or even further).
I've also included a marker that represents the kind of commercial relationships encountered in today's western society. Now we're on the “Visible to some” part of the visibility spectrum. In some cases (e.g. our dealings with lawyers), this marker would hopefully be located further to the left, indicating fewer parties to the information. The current location implies some overlapping of context and sharing across parties – for example, transactions visible to credit card companies, merchants, and third parties in their employ.
Going forward, I'll look at what happens as the dynamic towards data joining asserts itself in this model.
I found it a bit shocking when I plugged friendfeed, twitter, facebook, and digg together and saw comments I made years ago on digg suddenly displayed on all these sites. I immediately realized that I did not fully understand what I had just done. Who could see this stuff? Will they think I just “said” that now? Which passwords did I use? I was slowly getting a grip and thinking it through and I went back to facebook to find a conversation going on in chinese on my profile! It's a little embarrasing to admit that I changed 7 or 8 passwords within 10 minutes.
In a previous project I'd learned a lot of lessons about identity management having found myself caring for a somewhat sensitive provisioning application. (This site was key in understanding some of these concepts.) From my admittedly green point of view, it seems that a significant wave is forming and I know that CardSpace is ready and that it's the right thing for everyone.
good luck!