For the last several years I’ve been working on a new technology and capability that we are calling “Azure Active Directory B2C.” I’m delighted that I’m finally able to tell you about it, and share the ideas behind it.
For me it is the next step in the journey to give individual consumers, enterprises and governments the identity systems they need in this period of continuously more digital interaction and increasing threats to our security and privacy.
I don’t normally put official Microsoft content on these pages, but given how important the B2C initiative is, how closely I’ve been involved, and how well it has been received, I think it makes sense to show you Microsoft’s announcement about “B2C Basic”. It appeared on the Azure Active Directory Blog. Stuart Kwan does a great job of introducing you to the product.
I hope you’ll take a look at his introduction. I’ll be posting a number of pieces which expand on it – exploring issues we faced, giving you the background on the thinking behind the architecture and implementation, and telling you about the “B2C Premium” offering that is coming soon. I think the combination of Basic’s accessibility and Premium’s feature completeness really offers a new paradigm and amazing opportunities for everyone.
Introducing Microsoft Azure Active Directory B2C
By Stuart Kwan
With Azure Active Directory B2C we’re extending Azure AD to address consumer identity management for YOUR applications:
- Essential identity management for web, PC, and mobile apps: Support sign in to your application using popular social networks like Facebook or Google, or create accounts with usernames and passwords specifically for your application. Self-service password management and profile management are provided out of the box. Phone-based multi-factor authentication enables an extra measure of protection.
- Highly customizable and under your control: Sign up and sign in experiences are in the critical path of the most important activities in your applications. B2C gives you a high degree of control over the look and feel of these experiences, while at the same time reducing the attack surface area of your application – you never have to handle a user’s password. Microsoft is completely under the covers and not visible to your end users. Your user data belongs to you, not Microsoft, and is under your control.
- Proven scalability and availability: Whether you have hundreds of users or hundreds of millions of users, B2C is designed to handle your load, anywhere in the world. Azure AD is deployed in more than two dozen datacenters, and services hundreds of millions of users with billions of authentications per day. Our engineers monitor the service 24/7.
- Unique user protection features: Microsoft invests deeply in protection technology for our users. We have teams of domain experts that track the threat landscape. We’re constantly monitoring sign up and sign in activity to identify attacks and adapt our protection mechanisms. With B2C we’ll apply these anomaly, anti-fraud, and account compromise detection systems to your users.
- Pay as you go: Azure Active Directory is a global service benefiting from tremendous economies of scale, allowing us to pass these savings along to you. We offer the B2C service on a consumption basis – you only pay for the resources that you use. Developers can take advantage of the free tier of the service when building their application.
B2C uses the same familiar programming model of Azure Active Directory. You can quickly and easily connect your application to B2C using industry standards OAuth 2.0 and OpenID Connect for authentication, and OData v3 for user management via our Graph API. Web app, web API, mobile and PC app scenarios are fully supported. The same open source libraries that are used with Azure Active Directory can be used with B2C to accelerate development.
If you want, you can get started right now! The rest of this post takes a look at how B2C works in detail.
How it works
The best way to describe B2C is to see it in action. Let’s look at an example. Our heroes, Proseware, have a consumer-facing web site. The site uses B2C for identity management. In this case that means sign in, and user self-service sign up, profile management, and password reset. Here’s the Proseware homepage:
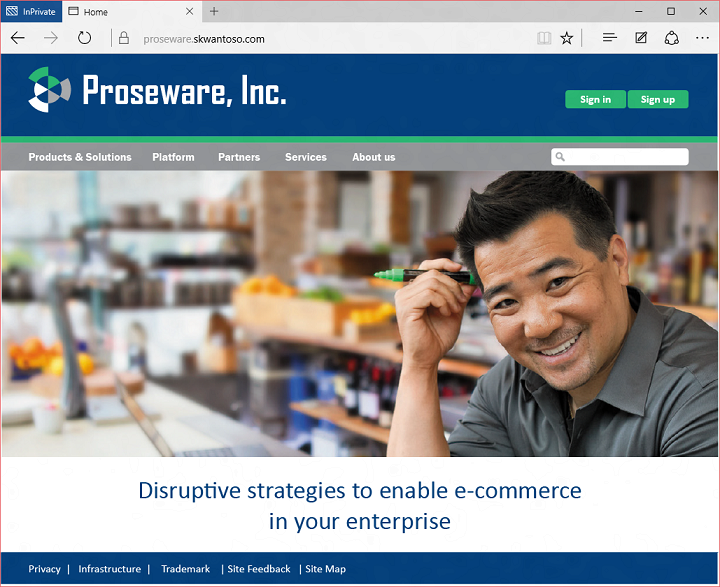
A new user would click sign up to create a new account. They have the choice of creating an account using Google, Facebook, or by creating a Proseware account:
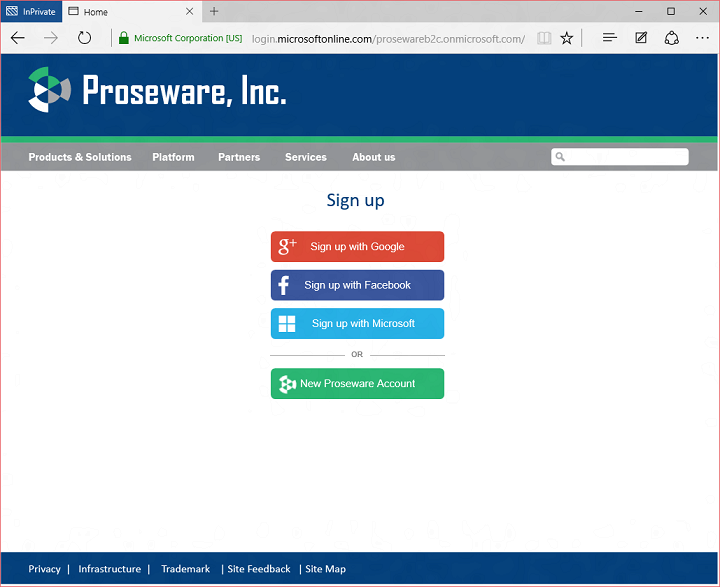
One quick note. The Microsoft button doesn’t work yet, but it will soon. It isn’t available at the start of the preview as we have more work to do in our converged programming model before we enable this.
What’s a Proseware account? As it turns out, there are many people out there who don’t always want to use a social account to sign in. You probably have your own personal decision tree for when you use your Facebook, Google, Microsoft or other social account to sign in, or when you create an account specifically for a site or app. In B2C a Proseware account is what we call a local account. It’s an account that gets created in the B2C tenant using an email address or a flat string as a username, and a password that is stored in the tenant. It’s local because it only works with apps registered in your B2C tenant. It can’t be used to sign in to Office 365, for example.
If a person decides to sign up with a social account, B2C uses information from the social account to pre-fill the user object that will be created in the B2C tenant, and asks the user for any other attributes configured by the developer:
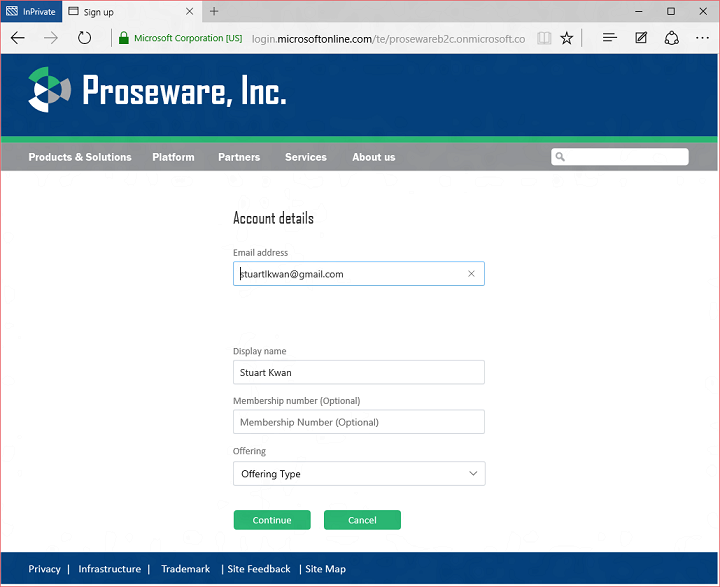
Here we can see the user is also asked to enter a Membership Number and Offering Type. These are custom attributes the Proseware developer has added to the schema of the B2C tenant.
If a person decides to sign up with a Proseware account, B2C gathers the attributes configured by the developer plus information needed to create a local account. In this case the developer has configured local accounts using email as username, so the person signing up is also asked to verify their email address:
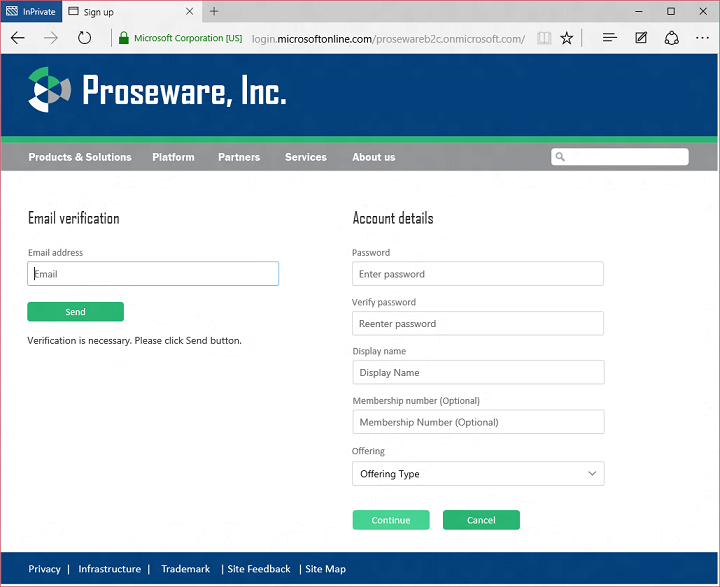
B2C takes care of verifying the person signing up has control of that email address before allowing them to proceed. Voila, the user is signed up and signed in to Proseware!
You might ask yourself, how much code did I need to write to make this elaborate sign up screen? Actually, almost none. The sign up page is being rendered by Azure AD B2C, not by the Proseware application. I didn’t have to write any code at all for the logic on that page. I only had to write the HTML and CSS so the page rendered with a Proseware look and feel. The logic for verifying the user’s email address and everything else on the page is B2C code. All I had to do was send an OpenID Connect request to B2C requesting the user sign up flow. I’ll go into more detail on this later when I talk about how I wrote the app and configured the B2C tenant.
Let’s look at a return visit. The user returns and clicks sign-in:
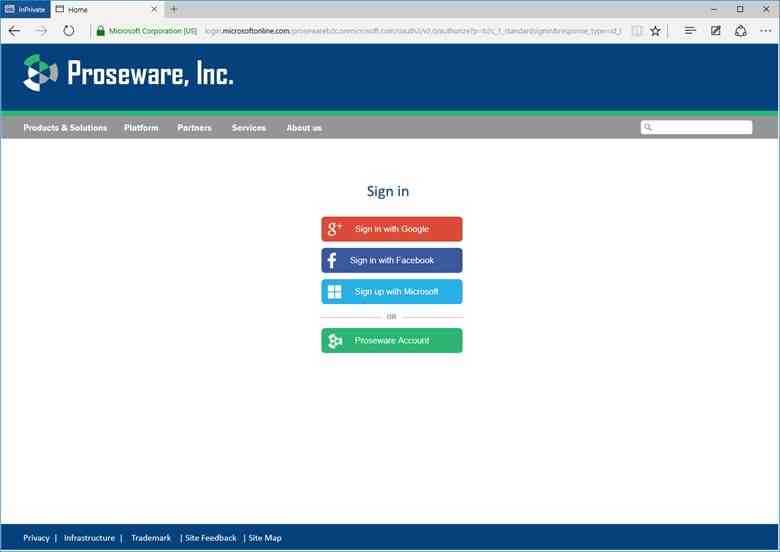
If the user clicks one of the social network providers, B2C will direct the person to the provider to sign in. Upon their return B2C also picks up attributes stored in the directory and returns them to the app, signing the user in.
If the user clicks the Proseware account button, they’ll see the local account sign in page, enter their name and password, and sign in:
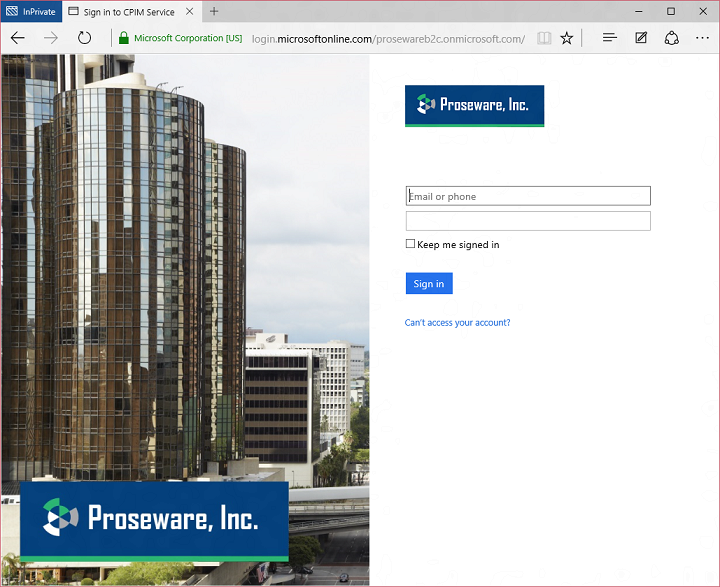
That’s it! Now I’ll show you how I built this example.
Configuring Azure AD B2C
Step one was to get an Azure AD B2C tenant. You can do this by going to the Azure AD section of the Azure management portal and creating a B2C tenant (for a shortcut, see the B2C getting started page). B2C tenants are a little different from regular Azure AD tenants. For example, in a regular tenant, by default users can see each other in the address book. That’s what you’d expect in a company or school – people can look each other up. In a B2C tenant, by default users cannot see each other in the address book. That’s what you’d expect – your consumer users shouldn’t be able to browse each other!
Once you have a B2C tenant, you register applications in the tenant and configure policies which drive the behavior of sign in, sign up, and other user experiences. Policies are the secret sauce of Azure AD B2C. To configure these policies, you jump through a link to the new Azure management portal:
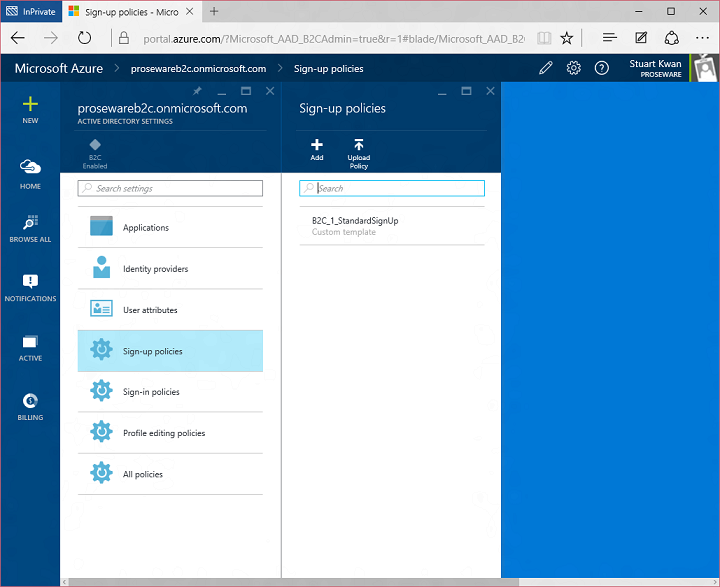
This is also the place where you find controls for setting up applications, social network providers, and custom attributes. I’m going to focus on sign up policy for this example. Here’s the list of sign up policies in the tenant. You can create more than one, each driving different behavior:
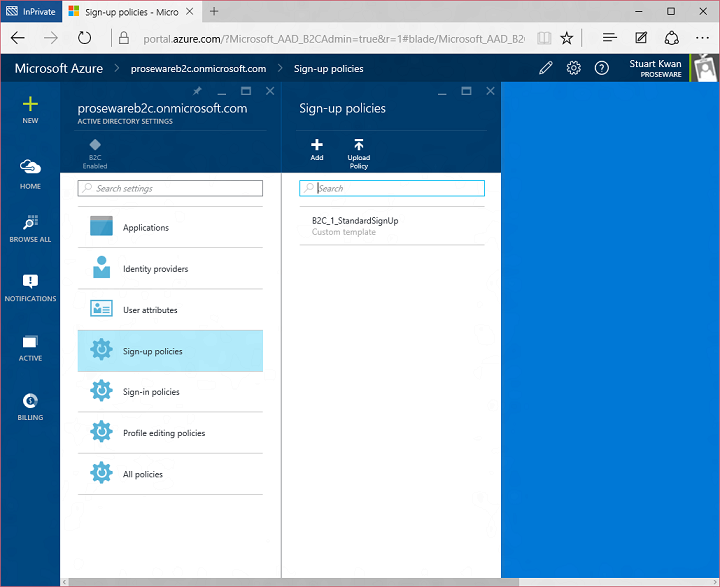
For the Proseware example I created the B2C_1_StandardSignUp policy. This policy allows a user to sign up using Facebook, Google, or email-named local accounts:
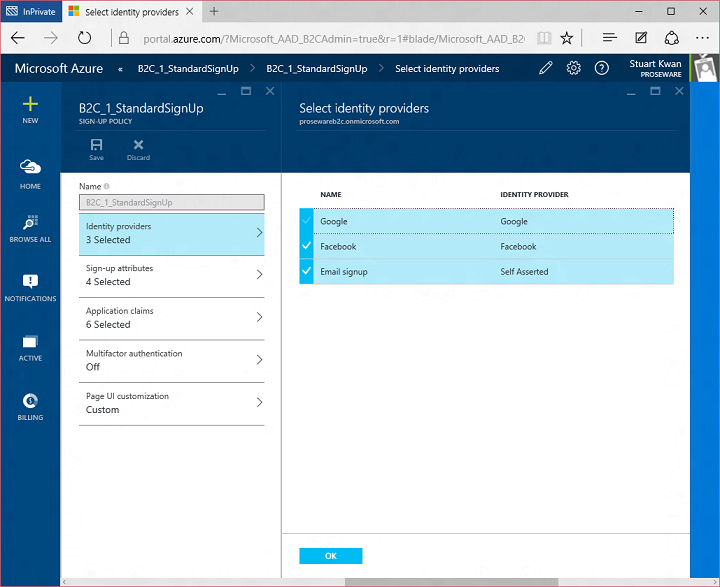
In sign up attributes I indicated what attributes should be gathered from the user during sign up. The list includes custom attributes I created earlier, Membership Number and Offering Type:
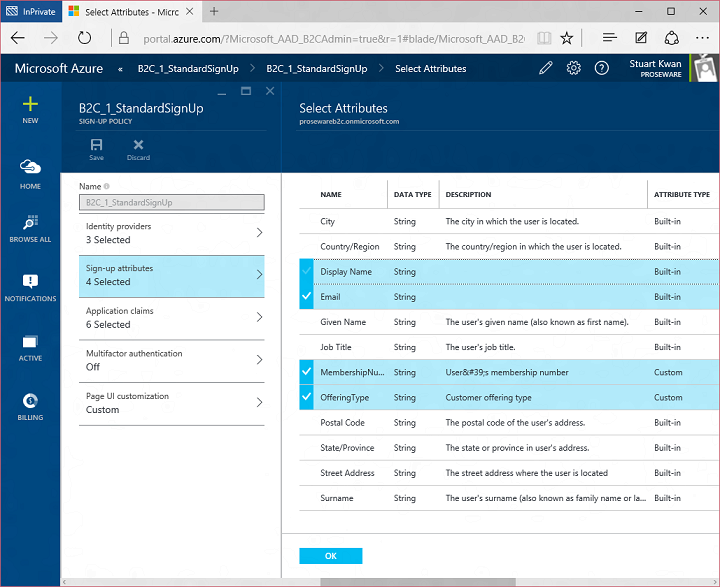
When a user completes sign up they are automatically signed in to the application. Using Application Claims I select what attributes I want to send to the application from the directory at that moment:
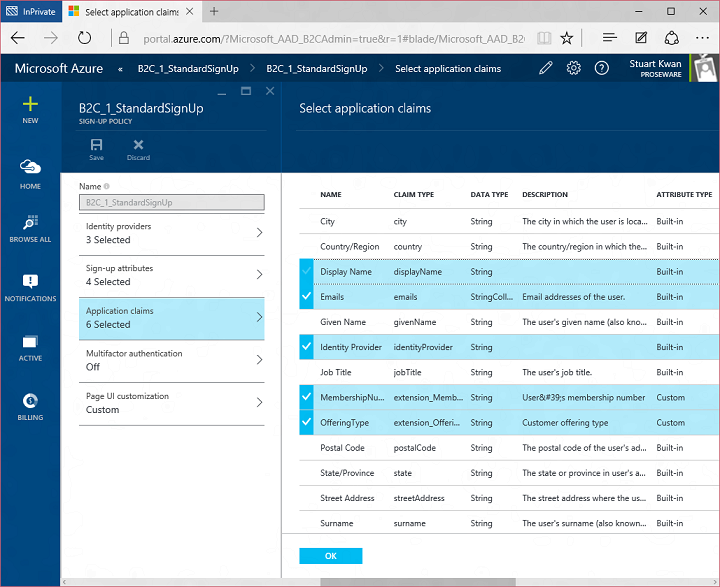
I’m not using multifactor authentication in this example, but if I did it’s just a simple on/off switch. During sign up the user would be prompted to enter their phone number and we would verify it in that moment.
Finally, I configured user experience customizations. You might have noticed that the sign up and sign-in experiences have a Proseware look and feel, and there isn’t much if any visual evidence of Microsoft or Azure AD. We know that for you to build compelling consumer-facing experiences you have to have as much control as possible over look and feel, so B2C is very customizable even in this initial preview. We do this by enabling you to specify HTML and CSS for the pages rendered by B2C. Here’s what the sign up page would look like with the default look and feel:
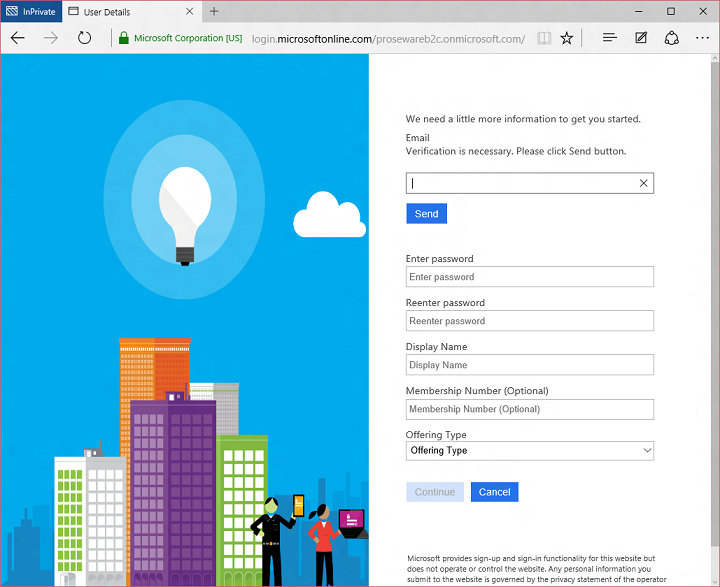
But if I configure a B2C with a URL to a web page I created with Proseware-specific look and feel:
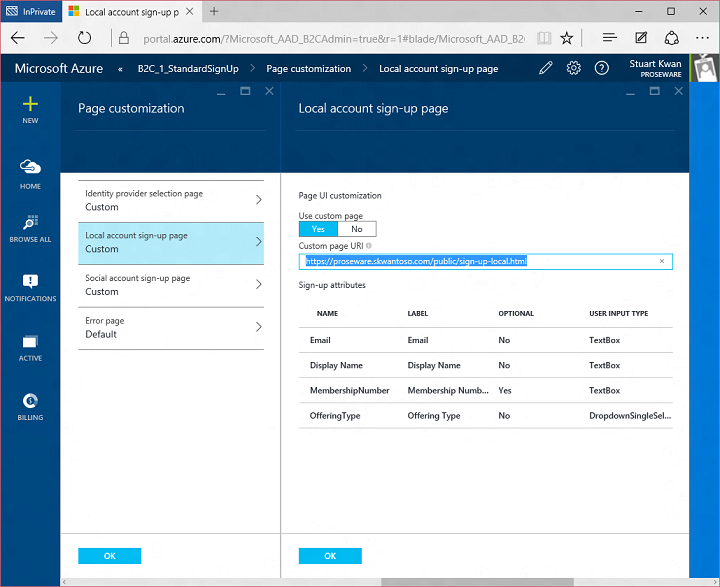
Then the sign up experience looks like this:
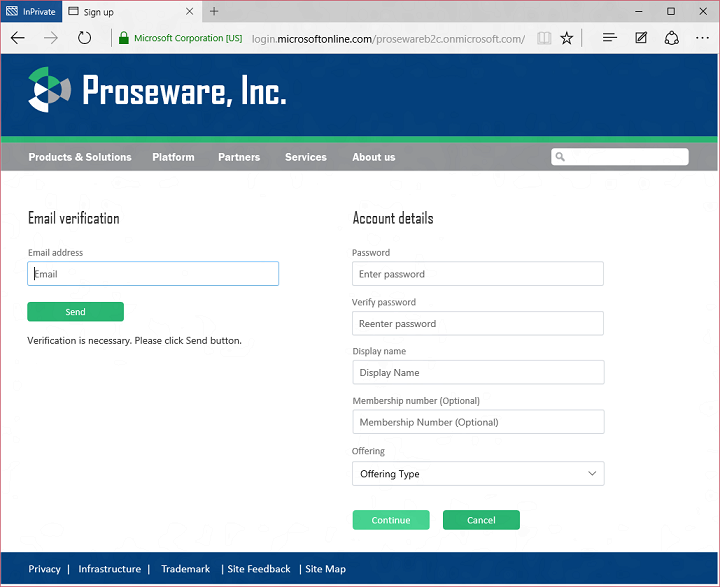
You can probably imagine a number of different approaches for this kind of customization. We’re partial to this approach, as opposed to say an API-based approach, because it means our servers are responsible for correct handling of things like passwords, and our protection systems can gather the maximum signal from the client for anomaly detection. In an API-based approach, your app would need to gather and handle passwords, and some amount of valuable signal would be lost.
One quick side note. In the initial preview it is possible to do HTML/CSS customization of all the pages except the local account sign in page. That page currently supports Azure AD tenant-branding style customization. We’ll be adding the HTML/CSS customization of the sign in page before GA. Also, we currently block the use of JavaScript for customization, but we expect to enable this later.
That’s a quick look at how I set up a sign up policy. Configuring other policies like sign in and profile management is very similar. As I mentioned earlier, you can create as many policies as you want, so you can trigger different behaviors even within the same app. How to do that? By requesting a specific policy at runtime! Let’s look at the code.
Building an app that uses B2C
The programming model for Azure AD B2C is super simple. Every request you send to B2C is an OAuth 2.0 or OpenID Connect request with one additional parameter, the policy parameter “p=”. This instructs B2C which policy you want to apply to the request. When someone clicks the sign up button on the Proseware web app, the app sends this OpenID Connect sign-in request:
GET /prosewareb2c.onmicrosoft.com/oauth2/v2.0/authorize?
response_type=id_token&
client_id=9bdade37-a70b-4eee-ae7a-b38e2c8a1416&
redirect_uri=https://proseware.skwantoso.com/auth/openid/return&
response_mode=form_post&
nonce= WzRMD9LC95HeHvDz&
scope=openid&
p=b2c_1_standardsignup
HTTP/1.1
The policy parameter in this example invokes the sign up policy called b2c_1_standardsignup. The OpenID Connect response contains an id_token as usual, carrying the claims I configured in the policy:
POST https://proseware.skwantoso.com/auth/openid/return HTTP/1.1
id_token=eyJ0eXAiOiJKV1QiLCJhbGciOiJSUzI1NiIsImtpZCI6IklkVG9rZW5TaWduaW5nS2V5Q29udGFpbmVyIn0.eyJleHAiOjE0NDIxMjc2OTYsIm5iZiI6MTQ0MjEyNDA5NiwidmVyIjoiMS4wIiwiaXNzIjoiaHR0cHM6Ly9sb2dpbi5taWNyb3NvZnRvbmxpbmUuY29tL2Q3YzM3N2RiLWY2MDktNDFmMy1iZTA5LTJiNzNkZWZkNDhhMC92Mi4wLyIsImFjciI6ImIyY18xX3N0YW5kYXJkc2lnbnVwIiwic3ViIjoiTm90IHN1cHBvcnRlZCBjdXJyZW50bHkuIFVzZSBvaWQgY2xhaW0uIiwiYXVkIjoiOWJkYWRlMzctYTcwYi00ZWVlLWFlN2EtYjM4ZTJjOGExNDE2Iiwibm9uY2UiOiJXelJNRDlMQzk1SGVIdkR6IiwiaWF0IjoxNDQyMTI0MDk2LCJhdXRoX3RpbWUiOjE0NDIxMjQwOTYsIm9pZCI6IjJjNzVkMWQ1LTU5YWYtNDc5Yi1hOWMzLWQ4NDFmZjI5ODIxNiIsImVtYWlscyI6WyJza3dhbkBtaWNyb3NvZnQuY29tIl0sImlkcCI6ImxvY2FsQWNjb3VudEF1dGhlbnRpY2F0aW9uIiwibmFtZSI6IlN0dWFydCBLd2FuIiwiZXh0ZW5zaW9uX01lbWJlcnNoaXBOdW1iZXIiOiIxMjM0IiwiZXh0ZW5zaW9uX09mZmVyaW5nVHlwZSI6IjEifQ.cinNfuoMCU4A2ZeeHBKLxAuc8B7UPKwd9sKngxQO8jy19ky3cAHhTJljO0KL7oQ1P5yMFQYs9i4hAun3mmL5hPyC3N7skjU9R0rYl91Ekk7QTlrYgDpGDp5uCF7eA-iWQr0Bmw8oUTYGpjrKfuQP2x8DFxiGgmFqkqz0a20-oy1R6Qr9PaSzr2r8KtjplPX97ADerKIBpdTeLRPmKILWqEDKzoG-bU40LULvPRdvA4yh4nlhRhn4CNUmjZfMWnBcCR3I6jBPl2M3qHQ10DoNXNe2qzL8GalzuMYNnG92OrUppZ5hmXRUXW9yrIRRzDGcERfRyrbyFuYPfu1JJBSTCA
Decoding the id_token from the response yields:
{
typ: “JWT”,
alg: “RS256”,
kid: “IdTokenSigningKeyContainer”
}.
{
exp: 1442127696,
nbf: 1442124096,
ver: “1.0”,
iss: “https://login.microsoftonline.com/d7c377db-f609-41f3-be09-2b73defd48a0/v2.0/”,
acr: “b2c_1_standardsignup”,
sub: “Not supported currently. Use oid claim.”,
aud: “9bdade37-a70b-4eee-ae7a-b38e2c8a1416”,
nonce: “WzRMD9LC95HeHvDz”,
iat: 1442124096,
auth_time: 1442124096,
oid: “2c75d1d5-59af-479b-a9c3-d841ff298216”,
emails: [
skwan@microsoft.com
],
idp: “localAccountAuthentication”,
name: “Stuart Kwan”,
extension_MembershipNumber: “1234”,
extension_OfferingType: “1”
}
Here you can see the usual claims returned by Azure Active Directory and also a few more. The custom attributes I added to the directory and requested of the user during sign up are returned in the token as extension_MembershipNumber and extension_OfferingType. You can also see the name of the policy that generated this token in the acr claim. By the way, we are in the process of taking feedback on claim type names and aligning ourselves better with the standard claim types in the OpenID Connect 1.0 specification. You should expect things to change here during the preview.
Since Azure AD B2C is in fact, Azure AD, it has the same programming model as Azure AD. Which means full support for web app, web API, mobile and PC app scenarios. Data in the directory is managed with the REST Graph API, so you can create, read, update, and delete objects the same way you can in a regular tenant. And this is super important – you can pick and choose what features and policies you want to use. If you want to build the user sign up process entirely yourself and manage users via the Graph API, you can absolutely do so.
B2C conforms to Azure AD’s next generation app model, the v2 app model. To build your application you can make protocol calls directly, or you can use the latest Azure Active Directory libraries that support v2. To find out more visit the B2C section of the Azure AD developer guide – we’ve got quickstart samples, libraries, and reference documentation waiting for you. Just for fun, I built the Proseware example using Node.js on an Ubuntu Linux virtual machine running on Microsoft Azure (shout out to @brandwe for helping me with the code!).
How much will it cost?
B2C will be charged on a consumption basis. You pay only for the resources you use. There will be three meters, billed monthly:
- Number of user accounts in the directory
- Number of authentications
- Number of multi-factor authentications
An authentication is defined as any time an application requests a token for a resource and successfully receives that token (we won’t charge for unsuccessful requests). When you consider the OAuth 2.0 protocol, this counts as when a user signs in with a local account or social account, and also when an application uses a refresh token to get a new access token.
You can find the B2C pricing tiers on the Azure.com pricing page. There will be a free tier for developers who are experimenting with the service. The current B2C preview is free of charge and preview tenants are capped at 50,000 users. We can raise that cap for you on a case by case basis if you contact us. We’ll lift the cap when billing is turned on. Do you have hundreds of millions of users? No problem. Bring ’em on!
What’s next
We’ve already worked with many developers to build apps using Azure AD B2C as part of a private preview program. Along the way we’ve gathered a healthy backlog of features:
- Full UX customization: Not just the aforementioned HTML/CSS customization of the local account sign in page, but also the ability to have your URL appear in the browser for every page rendered by B2C. That will remove the last visible remnant of Microsoft from the UX.
- Localization: Of course you have users all over the world speaking many languages. Sign in, sign up, and other pages need to render appropriately using strings you provide in the languages you want to support.
- Token lifetime control: The ability to control the lifetimes of Access Tokens, ID Tokens and Refresh Tokens is important both for user experience and for you to tune your consumption rate.
- A hook at the end of sign up: A number of people have said they want the ability to check a user who is signing up against a record in a different system. A little hook at the end of sign up would allow them to do this, so we’re considering it.
- Support for more social networks.
- Support for custom identity providers: This would be the ability to, say, add an arbitrary SAML or OpenID Connect identity provider to the tenant.
- A variety of predefined reports: So that you can review the activity in your tenant at a glance and without having to write code to call an audit log API.
- And more, this is just a fraction of the list…
You can track our progress by following the What’s New topic in the B2C section of the Azure AD developer guide, which you can find in the documentation pages and also by following this blog.
By the way, the proper name of this preview is the Azure Active Directory B2C Basic preview. We’re planning a Premium offering as well, with features that take policies to the next level. But that’s for another blog post!
Please write us
We’re eager to hear your feedback! We monitor stackoverflow (tag: azure-active-directory) for development questions. If you have a feature suggestion, please post it in the Azure Active Directory User Voice site and put “AADB2C:” in the title of your suggestion.
Stuart Kwan (Twitter: @stuartkwan)
Principal Program Manager
Azure Active Directory

 Today I’d like to build on Stuart’s introduction by explaining why we saw a customizable, policy-based approach to B2C as being essential – and what it means for the rest of our identity architecture. This will help you understand how our B2C Basic offering, now in public preview, actually works. It will also provide insight into the capabilities of our upcoming B2C Premium offering, currently in private preview with Marquee customers. I think it will become evident that the combination of our Basic and Premium products will represent a substantial step forward for the industry. It means organizations of any size can handle all their different customer relationships, grow without limitation, gain exceptional control of user experience and still dramatically reduce risk, cost, and complexity.
Today I’d like to build on Stuart’s introduction by explaining why we saw a customizable, policy-based approach to B2C as being essential – and what it means for the rest of our identity architecture. This will help you understand how our B2C Basic offering, now in public preview, actually works. It will also provide insight into the capabilities of our upcoming B2C Premium offering, currently in private preview with Marquee customers. I think it will become evident that the combination of our Basic and Premium products will represent a substantial step forward for the industry. It means organizations of any size can handle all their different customer relationships, grow without limitation, gain exceptional control of user experience and still dramatically reduce risk, cost, and complexity.

 @travisspencer: @NishantK But if it’s SaaS reading and/or writing, then I agree, it’s not provisioning /cc @johnshew @IdentityMonk @JohnFontana
@travisspencer: @NishantK But if it’s SaaS reading and/or writing, then I agree, it’s not provisioning /cc @johnshew @IdentityMonk @JohnFontana











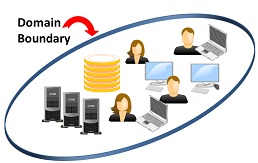 Enterprise identity technology evolved incrementally from mainframe days using the concept of administrative and security “domains”: collections of resources tightly integrated under a single, closed organizational administration.
Enterprise identity technology evolved incrementally from mainframe days using the concept of administrative and security “domains”: collections of resources tightly integrated under a single, closed organizational administration.