
New York TImes Technology ran a story yesterday about the publishing industry that is brimming with implications for almost everyone in the Internet economy. It is about Amazon and what marketing people call “disintermediation”. Not the simple kind that was the currency of the dot.com boom; we are looking here at a much more advanced case:
SEATTLE — Amazon.com has taught readers that they do not need bookstores. Now it is encouraging writers to cast aside their publishers.
Amazon will publish 122 books this fall in an array of genres, in both physical and e-book form. It is a striking acceleration of the retailer’s fledging publishing program that will place Amazon squarely in competition with the New York houses that are also its most prominent suppliers.
It has set up a flagship line run by a publishing veteran, Laurence Kirshbaum, to bring out brand-name fiction and nonfiction…
Publishers say Amazon is aggressively wooing some of their top authors. And the company is gnawing away at the services that publishers, critics and agents used to provide…
Of course, as far as Amazon executives are concerned, there is nothing to get excited about:
“It’s always the end of the world,” said Russell Grandinetti, one of Amazon’s top executives. “You could set your watch on it arriving.”
But despite the sarcasm, shivers of disintermediation are going down the spines of many people in the publishing industry:
“Everyone’s afraid of Amazon,” said Richard Curtis, a longtime agent who is also an e-book publisher. “If you’re a bookstore, Amazon has been in competition with you for some time. If you’re a publisher, one day you wake up and Amazon is competing with you too. And if you’re an agent, Amazon may be stealing your lunch because it is offering authors the opportunity to publish directly and cut you out. ” [Read whole story here.]
If disintermediation is something you haven't thought about much, you might start with a look at wikipedia:
In economics, disintermediation is the removal of intermediaries in a supply chain: “cutting out the middleman”. Instead of going through traditional distribution channels, which had some type of intermediate (such as a distributor, wholesaler, broker, or agent), companies may now deal with every customer directly, for example via the Internet. One important factor is a drop in the cost of servicing customers directly.
Note that the “removal” normally proceeds by “inserting” someone or something new into transactions. We could call the elimination of bookstores “first degree disintermediation” – the much-seen phenomenon of replacement of the existing distribution channel. But it seems intuitively right to call the elimination of publishers “second degree disintermediation” – replacement of the mechanisms of production, including everything from product development through physical manufacturing and marketing, by the entities now predominating in distribution.
The parable here is one of first degree disintermediation “spontaneously” giving rise to second degree disintermediation, since publishers have progressively less opportunity to succeed in the mass market without Amazon as time goes on. Of course nothing ensures that Amazon's execution will cause it to succeed in a venture quite different from its current core competency. But clearly the economic intrinsics stack the deck in its favor. Even without displacing its new competitors it may well skim off the most obvious and profitable projects, with the inevitable result of underfunding what remains.
I know. You're asking what all this has to do with identityblog.
In my view, one of the main problems of reusable identities is that in systems like SAML, WS-Federation and Live ID, the “identity provider” has astonishing visibility onto the user's relationship with the relying parties (e.g. the services who reuse the identity information they provide). Not only does the identity provider know what consumers are visiting what services; it knows the frequency and patterns of those visits. If we simply ignore this issue and pretend it isn't there, it will become an Achilles Heel.
Let me fabricate an example so I can be more concrete. Suppose we arrive at a point where some retailer decides to advise consumers to use their Facebook credentials to log in to its web site. And let's suppose the retailer is super successful. With Facebook's redirection-based single sign-on system, Facebook would be able to compile a complete profile of the retailer's customers and their log-on patterns. Combine this with the intelligence from “Like” buttons or advertising beacons and Facebook (or equivalent) could actually mine the profiles of users almost as effectively as the retailer itself. This knowledge represents significant leakage of the retailer's core intellectual property – its relationships with its customers.
All of this is a recipe for disintermediation of the exact kind being practiced by Amazon, and at some point in the process, I predict it will give rise to cases of spine-tingling that extend much more broadly than to a single industry like publishing.
By the time this becomes obvious as an issue we can also predict there will be broader understanding of “second degree disintermediation” among marketers. This will, in my view, bring about considerable rethinking of some current paradigms about the self-evident value of unlimited integration into social networks. Paradoxically disintermediation is actually a by-product of the privacy problems of social networks. But here it is not simply the privacy of end users that is compromised, but that of all parties to transactions.
This problem of disintermediation is one of the phenomena leading me to conclude that minimal disclosure technologies like U-Prove and Idemix will be absolutely essential to a durable system of reusable identities. With these technologies, the ability of the identity provider to disintermediate is broken, since it has no visibility onto the transactions carried out by individual users and cannot insert itself into the relationship between the other parties in the system.
Importantly, while disintermediation becomes impossible, it is still possible to meter the use of credentials by users without any infringement of privacy, and therefore to build a viable business model.
I hope to write more about this more going forward, and show concretely how this can work.

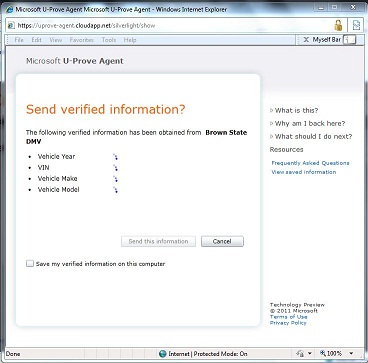 The system takes a number of the good ideas from CardSpace but is also informed by what CardSpace didn’t do well. It doesn’t require the installation of new components on your computer. It works on all the major browsers and phones. It roams between devices. Sites don't have to worry about users “getting a card” before the system will work. And it allows claims providers and relying parties to shape and brand their users’ experiences while still providing a consistent interface for claims approval.
The system takes a number of the good ideas from CardSpace but is also informed by what CardSpace didn’t do well. It doesn’t require the installation of new components on your computer. It works on all the major browsers and phones. It roams between devices. Sites don't have to worry about users “getting a card” before the system will work. And it allows claims providers and relying parties to shape and brand their users’ experiences while still providing a consistent interface for claims approval. If you are a programmer interested in identity, I doubt you'll find a more instructive or amusing video than
If you are a programmer interested in identity, I doubt you'll find a more instructive or amusing video than