Ray Corrigan routinely combines legal and technological insight at B2fxxx – Random thoughts on law, the Internet and society, and his book on Digital Decision Making is essential. His work often leaves me feeling uncharacteristically optimistic – living proof that a new kind of legal thinker is emerging with the technological depth needed to be a modern day Solomon.
I hadn't noticed the UK's new Protection of Freedoms Bill until I heard cabinet minister Damian Green talk about it as he pulverized the UK's centralized identity database recently. Naturally I turned to Ray Corrigan for comment, only to discover that the political housecleaning had also swept away the assumptions behind widespread fingerprinting in Britain's schools, reinstating user control and consent.
According to TES Connect:
The new Protection of Freedoms Bill gives pupils in schools and colleges the right to refuse to give their biometric data and compels schools to make alternative provision for them. The several thousand schools that already use the technology will also have to ask permission from parents retrospectively, even if their systems have been established for years…
It turns out that Britain's headmasters, apparently now a lazy bunch, have little stomach for trivialities like civil liberties. And writing about this, Ray's tone seems that of a judge who has had an impetuous and over-the-top barrister try to bend the rules one too many times. It is satisfying to see Ray send them home to study the Laws of Identity as scientific laws governing identity systems. I hope they catch up on their homework…
The Association of School and College Leaders (ASCL) is reportedly opposing the controls on school fingerprinting proposed in the UK coalition government's Protection of Freedoms Bill.
I always understood the reason that unions existed was to protect the rights of individuals. That ASCL should give what they perceive to be their own members’ managerial convenience priority over the civil rights of kids should make them thoroughly ashamed of themselves. Oh dear – now head teachers are going to have to fill in a few forms before they abuse children's fundamental right to privacy – how terrible.
Although headteachers and governors at schools deploying these systems may be typically ‘happy that this does not contravene the Data Protection Act’, a number of leading barristers have stated that the use of such systems in schools may be illegal on several grounds. As far back as 2006 Stephen Groesz, a partner at Bindmans in London, was advising:
“Absent a specific power allowing schools to fingerprint, I'd say they have no power to do it. The notion you can do it because it's a neat way of keeping track of books doesn't cut it as a justification.”
The recent decisions in the European Court of Human rights in cases like S. and Marper v UK (2008 – retention of dna and fingerprints) and Gillan and Quinton v UK (2010 – s44 police stop and search) mean schools have to be increasingly careful about the use of such systems anyway. Not that most schools would know that.
Again the question of whether kids should be fingerprinted to get access to books and school meals is not even a hard one! They completely decimate Kim Cameron's first four laws of identity.
1. User control and consent – many schools don't ask for consent, child or parental, and don't provide simple opt out options
2. Minimum disclosure for constrained use – the information collected, children's unique biometrics, is disproportionate for the stated use
3. Justifiable parties – the information is in control of or at least accessible by parties who have absolutely no right to it
4. Directed identity – a unique, irrevocable, omnidirectional identifier is being used when a simple unidirectional identifier (eg lunch ticket or library card) would more than adequately do the job.
It's irrelevant how much schools have invested in such systems or how convenient school administrators find them, or that the Information Commissioner's Office soft peddled their advice on the matter (in 2008) in relation to the Data Protection Act. They should all be scrapped and if the need for schools to wade through a few more forms before they use these systems causes them to be scrapped then that's a good outcome from my perspective.
In addition just because school fingerprint vendors have conned them into parting with ridiculous sums of money (in school budget terms) to install these systems, with promises that they are not really storing fingerprints and they can't be recreated, there is no doubt it is possible to recreate the image of a fingerprint from data stored on such systems. Ross, A et al ‘From Template to Image: Reconstructing Fingerprints from Minutiae Points’ IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 29, No. 4, April 2007 is just one example of how university researchers have reverse engineered these systems. The warning caveat emptor applies emphatically to digital technology systems that buyers don't understand especially when it comes to undermining the civil liberties of our younger generation.




 “NASCAR” approach of presenting a bunch of different buttons that redirect the user to, uh, something-or-other-that-can-be-phished, ahem, in spite of the privacy and security problems. This part of the conversation will go on for some time, since these problems will become progressively more widespread as NASCAR gains popularity and the criminally inclined tune in to its potential as a gold mine… But that discussion is for another day.
“NASCAR” approach of presenting a bunch of different buttons that redirect the user to, uh, something-or-other-that-can-be-phished, ahem, in spite of the privacy and security problems. This part of the conversation will go on for some time, since these problems will become progressively more widespread as NASCAR gains popularity and the criminally inclined tune in to its potential as a gold mine… But that discussion is for another day. 

 Last summer I
Last summer I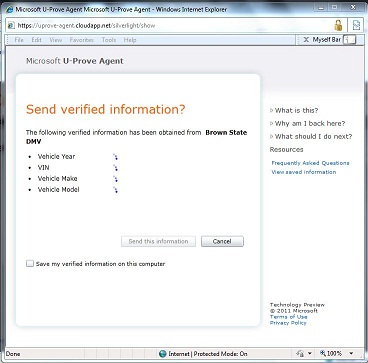 The system takes a number of the good ideas from CardSpace but is also informed by what CardSpace didn’t do well. It doesn’t require the installation of new components on your computer. It works on all the major browsers and phones. It roams between devices. Sites don't have to worry about users “getting a card” before the system will work. And it allows claims providers and relying parties to shape and brand their users’ experiences while still providing a consistent interface for claims approval.
The system takes a number of the good ideas from CardSpace but is also informed by what CardSpace didn’t do well. It doesn’t require the installation of new components on your computer. It works on all the major browsers and phones. It roams between devices. Sites don't have to worry about users “getting a card” before the system will work. And it allows claims providers and relying parties to shape and brand their users’ experiences while still providing a consistent interface for claims approval.


 If you are a programmer interested in identity, I doubt you'll find a more instructive or amusing video than
If you are a programmer interested in identity, I doubt you'll find a more instructive or amusing video than