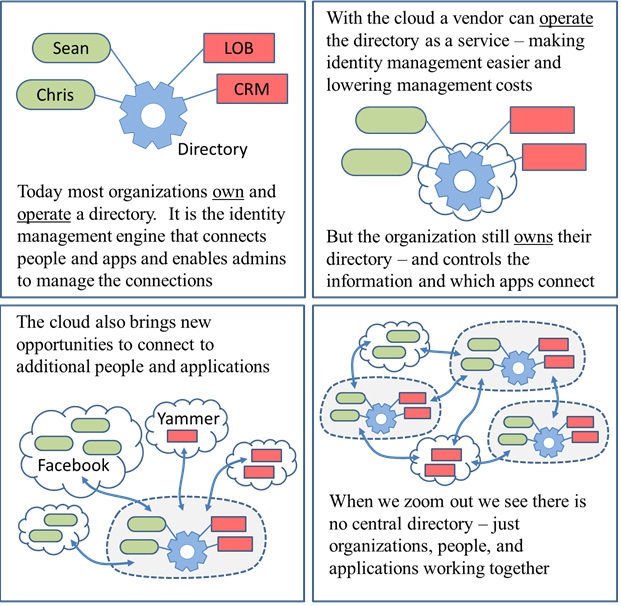
Today Alex Simons, Director of Program Management for Active Directory, posted the links to the Developer Preview of Windows Azure Active Directory. Another milestone.
I'll write about the release in my next post. Today, since the Developer Preview focuses a lot of attention on our Graph API, I thought it would be a good idea to respond first to the discussion that has been taking place on Twitter about the relationship between the Graph API and SCIM (Simple Cloud Identity Management).
Since the River of Tweets flows without beginning or end, I'll share some of the conversation for those who had other things to do:
@NishantK: @travisspencer IMO, @johnshew’s posts talk about SaaS connecting to WAAD using Graph API (read, not prov) @IdentityMonk @JohnFontana
@travisspencer: @NishantK Check out @vibronet’s TechEd Europe talk on @ch9. It really sounded like provisioning /cc @johnshew @IdentityMonk @JohnFontana
@travisspencer: @NishantK But if it’s SaaS reading and/or writing, then I agree, it’s not provisioning /cc @johnshew @IdentityMonk @JohnFontana
@travisspencer: @NishantK But even read/write access by SaaS *could* be done w/ SCIM if it did everything MS needs /cc @johnshew @IdentityMonk @JohnFontana
@NishantK: @travisspencer That part I agree with. I previously asked about conflict/overlap of Graph API with SCIM @johnshew @IdentityMonk @JohnFontana
@IdentityMonk: @travisspencer @NishantK @johnshew @JohnFontana check slide 33 of SIA322 it is really creating new users
@IdentityMonk: @NishantK @travisspencer @johnshew @JohnFontana it is JSON vs XML over HTTP… as often, MS is doing the same as standards with its own
@travisspencer: @IdentityMonk They had to ship, so it’s NP. Now, bring those ideas & reqs to IETF & let’s get 1 std for all @NishantK @johnshew @JohnFontana
@NishantK: @IdentityMonk But isn’t that slide talking about creating users in WAAD (not prov to SF or Webex)? @travisspencer @johnshew @JohnFontana
@IdentityMonk: @NishantK @travisspencer @johnshew @JohnFontana indeed. But its like they re one step of 2nd phase. What are your partners position on that?
@IdentityMonk: @travisspencer @NishantK @johnshew @JohnFontana I hope SCIM will not face a #LetTheWookieWin situation
@NishantK: @johnshew @IdentityMonk @travisspencer @JohnFontana Not assuming anything about WAAD. Wondering about overlap between SCIM & Open Graph API
Given these concerns, let me explain what I see as the relationship between SCIM and the Graph API.
What is SCIM?
All the SCIM documents begin with a commendably unambiguous statement of what it is:
The Simple Cloud Identity Management (SCIM) specification is designed to make managing user identity in cloud based applications and services easier. The specification suite seeks to build upon experience with existing schemas and deployments, placing specific emphasis on simplicity of development and integration, while applying existing authentication, authorization and privacy models. Its intent is to reduce the cost and complexity of user management operations by providing a common user schema and extension model, as well as binding documents to provide patterns of exchanging this schema using standard protocols. In essence, make it fast, cheap and easy to move users in to, out of and around the cloud. [Kim: emphasis is mine]
I support this goal. Further, I like the concept of spec writers being crisp about the essence of what they are doing: “Make it fast, cheap and easy to move users in to, out of and around the cloud”. For this type of spec to be useful we need it to be as widely adopted as possible, and that means keeping it constrained, focussed and simple enough that everyone chooses to implement it.
I think the SCIM authors have done important work to date. I have no comments on the specifics of the protocol or schema at this point – I assume those will continue to be worked out in accordance with the spec's “essence statement” and be vetted by a broad group of players now that SCIM is on a track towards standardization. Microsoft will try to help move this forward: Tony Nadalin will be attending the next SCIM meeting in Vancouver on our behalf.
Meanwhile, what is “the Graph”?
Given that SCIM's role is clear, let's turn to the question of how it relates to a “Graph API”.
Why does our thinking focus on a Graph API in addition to a provisioning protocol like SCIM? There are two answers.
Let's start with the theoretical one. It is because of the central importance of graph technology in being able to manage connectedness – something that is at the core of the digital universe. Treating the world as a graph allows us to have a unified approach to querying and manipulating interconnected objects of many different kinds that exist in many different relationships to each other.
But theory only appeals to some… So let's add a second answer that is more… practical. A directory has emerged that by August is projected to contain one billion users. True, it's only one directory in a world with many directories (most agree too many). But beyond the importance it achieves through its scale, it fundamentally changes what it means to be a directory: it is a directory that surfaces a multi-dimensional network.
This network isn't simply a network of devices or people. It's a network of people and the actions they perform, the things they use and create, the things that are important to them and the places they go. It's a network of relationships between many meaningful things. And the challenge is now for all directories, in all domains, to meet a new bar it has set.
Readers who come out of a computer science background are no doubt familiar with what a graph is. But I recommend taking the time to come up to speed on the current work on connectedness, much of which is summarized in Networks, Crowds and Markets: Reasoning About a Highly Connected World (by Easley and Kleinberg). The thesis is straightforward: the world of technology is one where everything is connected with everything else in a great many dimensions, and by refocusing on the graph in all its diversity we can begin to grasp it.
In early directories we had objects that represented “organizations”, “people”, “groups” and so on. We saw organizations as “containing” people, and saw groups as “containing” people and other groups in a hierarchical and recursive fashion. The hierarchy was a particularly rigid kind of network or graph that modeled the rigid social structures (governments, companies) being described by technology at the time.
But in today's flatter, more interconnected world, the things we called “objects” in the days of X.500 and LDAP are better expressed as “nodes” with different kinds of “edges” leading to many possible kinds of other “nodes”. Those who know my work from around 2000 may remember I used to call this polyarchy and contrast it with the hierarchical limitations of LDAP directory technology.
From a graph perspective we can see “person nodes” having “membership edges” to “group nodes”. Or “person nodes” having “friend edges” to other “person nodes”. Or “person nodes” having “service edges” to a “mail service node”. In other words the edges are typed relationships between nodes that may possibly contain other properties. Starting from a given node we can “navigate the graph” across different relationships (I think of them as dimensions), and reason in many new ways.
For example, we can reason about the strength of the relationships between nodes, and perform analysis, understand why things cluster together in different dimensions, and so on.
From this vantage point, directory is a repository of nodes that serve as points of entry into a vast graph, some of which are present in the same repository, and others of which can only be reached by following edges that point to resources in different repositories. We already have forerunners of this in today's directories – for example, if the URL of my blog is contained in my directory entry it represents an edge leading to another object. But with conventional technology, there is a veil over that distant part of the graph (my blog). We can read it in a browser but not access the entities it contains as structured objects. The graph paradigm invites us to take off the veil, making it possible to navigate nodes across many dimensions.
The real power of directory in this kind of interconnected world is its ability to serve as the launch pad for getting from one node to a myriad of others by virtue of different relationships.
This requires a Graph Protocol
To achieve this we need a simple, RESTful protocol that allows use of these launch pads to enter a multitude of different dimensions.
We already know we can build a graph with just HTTP REST operations. After all, the web started as a graph of pages… The pages contained URLs (edges) to other pages. It is a pretty simple graph but that's what made it so powerful.
With JSON (or XML) the web can return objects. And those objects can also contain URLs. So with just JSON and HTTP you can have a graph of things. The things can be of different kinds. It's all very simple and very profound.
No technology ghetto
Here I'm going to put a stake in the ground. When I was back at ZOOMIT we built the first commercial implementation of LDAP while Tim Howes was still at University of Michigan. It was a dramatic simplification relative to X.500 (a huge and complicated standard that ZOOMIT had also implemented) and we were all very excited at how much Tim had simplified things. Yet in retrospect, I think the origins of LDAP in X.500 condemned directory people to life in a technology ghetto. Much more dramatic simplifications were coming down the pike all around us in the form of HTML, latter day SQL and XML. For every 100 application programmers familiar with these technologies, there might have been – on a good day – one who knew something about LDAP. I absolutely respect and am proud of all the GOOD that came from LDAP, but I am also convinced that our “technology isolation” was an important factor that kept (and keeps) directory from being used to its potential.

So one of the things that I personally want to see as we reimagine directory is that every application programmer will know how to program to it. We know this is possible because of the popularity of the Facebook Graph API. If you haven't seen it close up and you have enough patience to watch a stream of consciousness demo you will get the idea by watching this little walkthrough of the Facebook Graph Explorer. Or better still just go here and try with your own account data.
You have to agree it is dead simple and yet does a lot of what is necessary to navigate the kind of graph we are talking about. There are many other similar explorers available out there – including ours. I chose Facebook's simply because it shows that this approach is already being used at colossal scale. For this reason it reveals the power of the graph as an easily understood model that will work across pretty much any entity domain – i.e. a model that is not technologically isolated from programming in general.
A pluggable namespace with any kind of entity plugging in
In fact, the Graph API approach taken by Facebook follows a series of discussions by people now scattered across the industry where the key concept was one of creating a uniform pluggable namespace with “any” kind of entity plugging in (ideas came from many sources including the design of the Azure Service Bus).
Nishant and others have posed the question as to whether such a multidimensional protocol could do what SCIM does. And my intuition is that if it really is multidimensional it should be able to provide the necessary functionality. Yet I don't think that diminishes in any way the importance of or the need for SCIM as a specialized protocol. Paradoxically it is the very importance of the multidimensional approach that explains this.
Let's have a thought experiment.
Let's begin with the assumption that a multidimensional protocol is one of the great requirements of our time. It then seems inevitable to me that we will continue to see the emergence of a number of different proposals for what it should be. Human nature and the angels of competition dictate that different players in the cloud will align themselves with different proposals. Ultimately we will see convergence – but that will take a while. Question: How are we do cloud provisioning in the meantime? Does everyone have to implement every multidimensional protocol proposal? Fail!
So pragmatism calls for us to have a widely accepted and extremely focused way of doing provisioning that “makes it fast, cheap and easy to move users in to, out of and around the cloud”.
Meanwhile, allow developers to combine identity information with information about machines, services, web sites, databases, file systems, and line of business applications through multidimensional protocols and APIs like the Facebook and the Windows Azure Active Directory Graph APIs. For those who are interested, you can begin exploring our Graph API here: Windows Azure AD Graph Explorer (hosted in Windows Azure) (Select ‘Use Demo Company’ unless you have your own Azure directory and have gone through the steps to give the explorer permission to see it…)
To me, the goals of SCIM and the goals of the Graph API are entirely complementary and the protocols should coexist peacefully. We can even try to find synergy and ways to make things like schema elements align so as to make it as easy as possible to move between one and the other.