Dave Kearns’ comment in Another Violent Agreement convinces me I've got to apply the scalpel to the way I talk about correlation handles. Dave writes:
‘I took Kim at his word when he talked “about the need to prevent correlation handles and assembly of information across contexts…” That does sound like “banning the tools.”
‘So I'm pleased to say I agree with his clarification of today:
;”I agree that we must influence behaviors as well as develop tools… [but] there’s a huge gap between the kind of data correlation done at a person’s request as part of a relationship (VRM), and the data correlation I described in my post that is done without a person’s consent or knowledge.” (Emphasis added by Dave)’
Thinking about this some more, it seems we might be able to use a delegation paradigm.
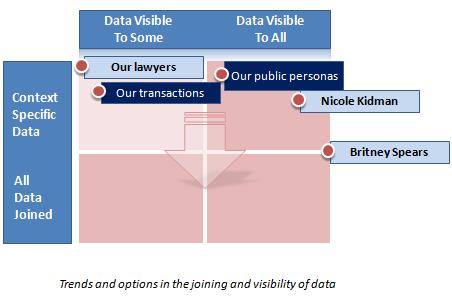
The “right to correlate”
Let's postulate that only the parties to a transaction have the right to correlate the data in the transaction (unless it is fully anonymized).
Then it would follow that any two parties with whom an individual interacts would not by default have the right to correlate data they had each collected in their separate transactions.
On the other hand, the individual would have the right to organize and correlate her own data across all the parties with whom she interacts since she was party to all the transactions.
Delegating the Right to Correlate
If we introduce the ability to delegate, then an individual could delegate her right for two parties to correlate relevant data about her. For example, I could delegate to Alaska Airlines and British Airways the right to share information about me.
Similarly, if I were an optimistic person, I could opt to use a service like that envisaged by Dave Kearns, which “can discern our real desires from our passing whims and organize our quest for knowledge, experience and – yes – material things in ways which we can only dream about now.” The point here is that we would delegate the right to correlate to this service operating on our behalf.
Revoking the Right to Correlate
A key aspect of delegating a right is the ability to revoke that delegation. In other words, if the service to which I had given some set of rights became annoying or odious, I would need to be able terminate its right to correlate. Importantly, the right applies to correlation itself. Thus when the right is revoked, the data must no longer be linkable in any way.
Forensics
There are cases where criminal activity is being investigated or proven where it is necessary for law enforcement to be able to correlate without the consent of the individual. This is already the case in western society and it seems likely that new mechanisms would not be required in a world resepcting the Right to Correlate.
Defining contexts
Respecting the Right to Correlate would not by itself solve the Canadian Tire Problem that started this thread. The thing that made the Canadian Tire human experiments most odious is that they correlated buying habits at the level of individual purchases (our relations to Canadian Tire as a store) with probable behavior in paying off credit cards (Canadian Tire as a credit card issuer). Paradoxically, someone's loyalty to the store could actually be used to deny her credit. People who get Canadian Tire credit cards do know that the company is in a position to correlate all this information, but are unlikely to predict this counter-intuitive outcome.
Those of us prefering mainstream credit card companies presumably don't have the same issues at this point in time. They know where we buy but not what we buy (although there may be data sharing relationships with merchants that I am not aware of… Let me know…).
So we have come to the the most important long-term problem: The Internet changes the rules of the game by making data correlation so very easy.
It potentially turns every credit card company into a data-correlating Canadian Tire. Are we looking at the Canadian Tirization of the Internet?
But do people care?
Some will say that none of this matters because people just don't care about what is correlated. I'll discuss that briefly in my next post.