Inspired by some of Ben Laurie's recent postings, I want to continue exploring the issues of privacy and linkability (see related pieces here and here).
I have explained that CardSpace is a way of selecting and transferring a relevant digital identity – not a crypto system; and that the privacy characteristics involved depend on the nature of the transaction and the identity provider being used within CardSpace – not on CardSpace itself. I ended my last piece this way:
The question now becomes that of how identity providers behave. Given that suddenly they have no visibility onto the relying party, is linkability still possible?
But before zeroing in on specific technologies, I want to drill into two issues. First is the meaning of “identification”; and second, the meaning of “linkability” and its related concept of “traceability”.
Having done this will allow us to describe different types of linkage, and set up our look at how different cryptographic approaches and transactional architectures relate to them.
Identification
There has been much discussion of identification (which, for those new to this world, is not at all the same as digital identity). I would like to take up the definitions used in the EU Data Protection Directive, which have been nicely summarized here, but add a few precisions. First, we need to broaden the definition of “indirect identification” by dropping the requirement for unique attributes – as long as you end up with unambiguous identification. Second, we need to distinguish between identification as a technical phenomenon and personal identification.
This leads to the following taxonomy:
- Personal data:
- any piece of information regarding an identified or identifiable natural person.
- Direct Personal Identification:
- establishing that an entity is a specific natural person through use of basic personal data (e.g., name, address, etc.), plus a personal number, a widely known pseudo-identity, a biometric characteristic such as a fingerprint, PD, etc.
- Indirect Personal Identification:
- establishing that an entity is a specific natural person through other characteristics or attributes or a combination of both – in other words, to assemble “sufficiently identifying” information
- Personal Non-Identification:
- assumed if the amount and the nature of the indirectly identifying data are such that identification of the individual as a natural person is only possible with the application of disproportionate effort, or through the assistance of a third party outside the power and authority of the person responsible…
Translating to the vocabulary we often use in the software industry, direct personal identification is done through a unique personal identifier assigned to a natural person. Indirect personal identification occurs when enough claims are released – unique or not – that linkage to a natural person can be accomplished. If linkage to a natural person is not possible, you have personal non-identification. We have added the word “personal” to each of these definitions so we could withstand the paradox that when pseudonyms are used, unique identifiers may in fact lead to personal non-identification…
The notion of “disproportionate effort” is an important one. The basic idea is useful, with the proviso that when one controls computerized systems end-to-end one may accomplish very complicated tasks, computations and correlations very easily – and this does not in itself constitute “disproportionate effort”.
Linkability
If you search for “linkability”, you will find that about half the hits refer to the characteristics that make people want to link to your web site. That's NOT what's being discussed here.
Instead, we're talking about being able to link one transaction to another.
The first time I heard the word used this way was in reference to the E-Cash systems of the eighties. With physical cash, you can walk into a store and buy something with one coin, later buy something else with another coin, and be assured there is no linkage between the two transactions that is caused by the coins themselves.
This quality is hard to achieve with electronic payments. Think of how a credit card or debit card or bank account works. Use the same credit card for two transactions and you create an electronic trail that connects them together.
E-Cash was proposed as a means of getting characteristics similar to those of the physical world when dealing with electronic transactions. Non-linkability was the concept introduced to describe this. Over time it has become a key concept of privacy research, which models all identity transactions as involving similar basic issues.
Linkability is closely related to traceability. By traceability people are talking about being able to follow a transaction through all its phases by collecting transaction information and having some way of identifying the transaction payload as it moves through the system.
Traceability is often explicitly sought. For example, with credit card purchases, there is a transaction identifier which ties the same event together across the computer systems of the participating banks, clearing house and merchant. This is certainly considered “a feature.” There are other, subtler, sometimes unintended, ways of achieving traceability (timestamps and the like).
Once you can link two transactions, many different outcomes may result. Two transactions conveying direct personal identification might be linked. Or, a transaction initially characterized by personal non-identification may suddenly become subject to indirect personal identification.
To further facilitate the discussion, I think we should distinguish various types of linking:
- Intra-transaction linking is the product of traceability, and provides visibility between the claims issuer, the user presenting the claims, and the relying party (for example, credit card transaction number).
- Single-site transaction linking associates a number of transactions at a single site with a data subject. The phrase “data subject” is used to clarify that no linking is implied between the transactions and any “natural person”.
- Multi-site transaction linking associates linked transactions at one site with those at another site.
- Natural person linking associates a data subject with a natural person.
Next time I will use these ideas to help explain how specific crypto systems and protocol approaches impact privacy.

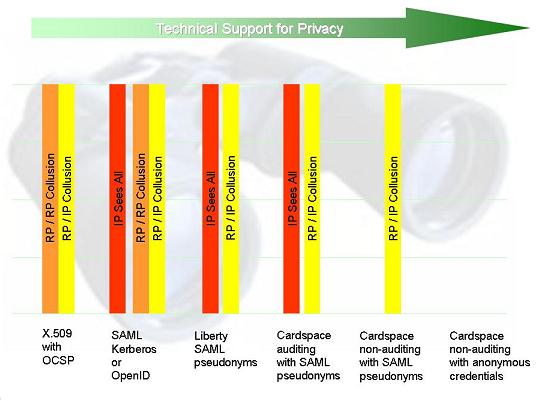
 What is good about X.509 is that if a relying party does not collude, the CA has no visibility onto the fact that a given user has visited it (we will see that in some other systems such visibility is unavoidable). But a relying party could at any point decide to collude with the CA (assuming the CA actually accepts such information, which may be a breach of policy). This might result in the transfer of information in either direction beyond that contained in the certificate itself.
What is good about X.509 is that if a relying party does not collude, the CA has no visibility onto the fact that a given user has visited it (we will see that in some other systems such visibility is unavoidable). But a relying party could at any point decide to collude with the CA (assuming the CA actually accepts such information, which may be a breach of policy). This might result in the transfer of information in either direction beyond that contained in the certificate itself.